kettle调度监控最佳实践
发布时间:2025-05-23 08:54:43 发布人:远客网络
一、kettle调度监控最佳实践
1、Kettle,这款用户规模最多的开源ETL工具,因其强大的功能而深受ETL从业者的喜爱。然而,Kettle的调度监控功能相对薄弱,Pentaho官方甚至推荐使用crontab(Unix平台)和计划任务(Windows平台)来实现调度功能。以下几种调度方式是常见实践:
2、一、spoon程序调用Job(kjb作业)
3、这是一条直接从Kettle内部调度的方式,可实现基本的定时调度功能,如按月、周、日、时点等方式启动。执行速度较快,但对ETL作业来说,它本质是后台数据处理,却要求spoon桌面程序持续运行。这对平台稳定性及自动化管理标准来说,是不理想的,因此企业通常不会选择此方案。
4、二、官方建议的crontab或计划任务
5、这是目前较为流行的方案,适合一般用户的基本调度需求。然而,对于复杂调度逻辑(如依赖、互斥、自定义条件分支、错误重试、断点续跑等高级特性)则难以应对。每次调用转换或作业,需要消耗大量时间(>10秒)来初始化新的Kettle运行环境。并行调用多个Kettle作业时,尤其是调用数据资源库中的作业,容易引发系统级错误,带来不稳定性。此外,初始化Kettle运行环境实质上是启动一个JVM进程,多个作业同时运行可能导致系统内存溢出,例如测试中5个转换的简单文本操作就已耗尽2GB内存。因此,此方案不适合并行调用多个Kettle作业。
6、三、自主开发Java程序调用Kettle类库
7、虽然可以提高调度效率,但自主开发解决方案需要投入较大的人力成本,特别是面对大规模作业调度需求时。这种方式还需额外开发监控和日志查看功能,后续维护成本也将显著增加。此外,即使采用流行框架如oozie,开发周期也可能长达6个人月。
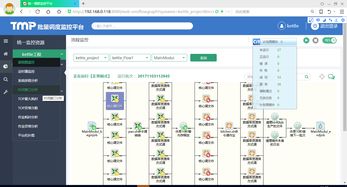
8、针对调度监控需求,存在更敏捷适用的解决方案,如TASKCTL。它实现了对Kettle作业的实时调度监控管理,提供了全面的调度核心,包括依赖、互斥、串并引用策略、排程计划策略、容错策略、自定义策略等。并且,它具备企业级特性,支持跨平台、分布式、高可靠管理,无论在Linux还是Windows系统上的Kettle作业都能统一监控。此外,它还提供了灵活的人工干预功能,如运行任意流程分支、断点、暂停、强制通过、重跑等,并且调度效率得到大幅度提升。使用TASKCTL调度Kettle,运行相同ktr的60次,传统方式耗时约21分15秒,而采用TASKCTL则不到5秒(并行度为20)。此外,TASKCTL提供了实时刷新、图形、多角度多口径统计以及短信等全方位实时监控方式,以便用户及时掌握作业运行状态。
9、为了解决调度监控问题,首先需要安装TASKCTL服务端、桌面客户端及Kettle插件和实例流程。对于具备一定Linux基础的用户,整个部署过程预计在30分钟内完成。
二、Kettle简介
1、Kettle,作为一款开源的ETL工具,对于数据处理、转换和迁移至关重要。它由纯Java编写,支持跨平台运行,且无需安装,以高效稳定著称。中文名称“水壶”的灵感来源于其创始人MATT的理念,旨在将各种数据整合到一个统一的“壶”中,以预设的格式输出。
2、Kettle的结构包括Spoon,一个图形化工具,用于设计和管理ETL作业与转换,通过拖拽实现,可调用数据集成引擎或集群。另外,Data Integration Server是一个专用的ETL服务器,拥有企业控制台,提供证书管理、监控和远程服务器活动的管理功能。
3、核心组件包括Job和Transformation,Job负责工作流程的控制,而Transformation则负责数据的基本转换,通过步骤完成读取、过滤、清洗和加载操作。数据流以行的形式在步骤间传递,通过"跳"定义单向数据通道。步骤是转换的基础,每个步骤都有独特名称,处理数据并连接到输出"跳"。
4、下载Kettle后,需要配置JDK和环境变量。通过Spoon.bat启动后,即可直观体验,如从CSV导入数据到Excel。Kettle利用可视化编程,通过图形化界面构建复杂的ETL工作流,降低维护难度。数据类型丰富多样,包括字符串、数字、日期等,每个步骤都有元数据描述,支持并行处理,以高效处理大量数据。
三、Kettle与NIFI差异 (2022-3-21)
1、Kettle是国外开源ETL工具,纯Java编写,支持Windows、Linux、Unix环境,无需安装,数据抽取高效稳定。Kettle的中文名称为水壶,由主程序员MATT设计,旨在将数据放入一个容器中,通过指定格式流出。Kettle工具集允许用户通过图形界面管理来自不同数据库的数据,无需详细描述实现方法。其核心功能包括transformation脚本用于基础数据转换,job脚本控制整个工作流程。Kettle由Spoon、Kitchen、Pan和Carte四个组件组成。Spoon是图形界面,用于开发转换和作业;Kitchen与Pan用于通过命令行调用Job与Trans;Carte是轻量级Web容器,建立专用、远程ETL服务。Kettle常用于处理关系型和非关系型数据库,提供全面的数据处理功能,包括全量与增量数据迁移、XML和JSON数据解析、数据关联比对、数据清洗转换等。
2、Apache NiFi是一个功能强大的自动化数据拉取、处理和分发系统,用于管理系统间的数据流。NiFi支持高度可配置的指示图数据路由、转换和系统中介逻辑,从多种数据源动态拉取数据。NiFi起源于NSA项目,现为Apache基金会顶级项目之一,基于Web方式工作。用户可以定义数据处理流程,后台具有数据处理引擎、任务调度等组件。NiFi的核心概念包括FlowFile、FlowFile Processor、Connection和Flow Controller等。NiFi提供可视化命令与控制、高度可配置、损失容忍与保证交付、低延迟与高吞吐量、动态优先、流修改、数据回压、数据溯源、多租户授权和安全等功能,支持快速开发、测试和扩展。
3、与Kettle相比,NiFi基于WEB的B/S架构,更易于集成。Kettle采用C/S架构,两者在数据处理功能、架构设计上各有优势。Kettle侧重于数据处理的灵活性与高效性,而NiFi则强调数据流的可视化与自动化管理,两者在实际应用中可根据特定需求进行选择或结合使用。