django如何连接es(django如何连接数据库mysql)
发布时间:2025-05-23 05:50:15 发布人:远客网络
一、django如何连接es(django如何连接数据库mysql)
本篇文章首席CTO笔记来给大家介绍有关django如何连接es以及django如何连接数据库mysql的相关内容,希望对大家有所帮助,一起来看看吧。
首先需要增加一个Completion字段
但由于使用ik_max_word,会出错,所以我们需要自己定义分析器,这样可以避免报错问题
那爬虫爬下的每一条数据是如何变成suggest值呢?我们在pipeline中定义生成建议的函数来处理字段(title和subjects,并附上各自的权重)
运行爬虫,我们可以在head中随便看一条数据,查看suggest的值:
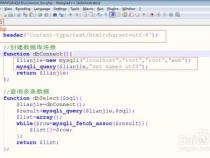
如何处理django的数据库连接池
由于创建连接的代价是很高的,我们每次访问数据库都重新创建连接的话是非常消耗性的.
由于创建连接的代价是很高的,我们每次访问数据库都重新创建连接的话是非常消耗性的.
我们可以再程序启动的时候先创建出一些连接,放在一个集合中,访问数据库的时候从集合中获取,使用结束再放回集合中.
这样做只是在程序启动的时候消耗性能去创建连接,每次访问数据库的时候都是从内存中获取连接,可以大大提升效率.
由于池中增删非常频繁,使用集合LinkedList效率较高
集合中所有连接都被占用时创建新连接,但需要注意连接总数
使用组合模式/动态代理处理释放连接的方法,当运行close方法时,将连接放回池中
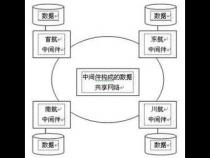
数据库连接是一种关键的有限的昂贵的资源,这一点在多用户的网页应用程序中体现得尤为突出。对数据库连接的管理能显著影响到整个应用程序的伸缩性和健壮性,影响到程序的性能指标。数据库连接池正是针对这个问题提出来的。
数据库连接池负责分配、管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而再不是重新建立一个;释放空闲时间超过最大空闲时间的数据库连接来避免因为没有释放数据库连接而引起的数据库连接遗漏。这项技术能明显提高对数据库操作的性能。
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
数据库连接池的最小连接数和最大连接数的设置要考虑到下列几个因素:
1)最小连接数是连接池一直保持的数据库连接,所以如果应用程序对数据库连接的使用量不大,将会有大量的数据库连接资源被浪费;
2)最大连接数是连接池能申请的最大连接数,如果数据库连接请求超过此数,后面的数据库连接请求将被加入到等待队列中,这会影响之后的数据库操作。
3)如果最小连接数与最大连接数相差太大,那么最先的连接请求将会获利,之后超过最小连接数量的连接请求等价于建立一个新的数据库连接。不过,这些大于最小连接数的数据库连接在使用完不会马上被释放,它将被放到连接池中等待重复使用或是空闲超时后被释放。
J2EE服务器启动时会建立一定数量的池连接,并一直维持不少于此数目的池连接。
调用:客户端程序需要连接时,池驱动程序会返回一个未使用的池连接并将其表记为忙。如果当前没有空闲连接,池驱动程序就新建一定数量的连接,新建连接的数量有配置参数决定。
释放:当使用的池连接调用完成后,池驱动程序将此连接表记为空闲,其他调用就可以使用这个连接
Django完全支持匿名Session。Session框架允许每一个用户保存并取回数据。它将数据保存在服务器端,并将发送和接收Cookie的操作包装起来。在Cookie中包含的是SessionID,而不是数据本身。
Session是通过中间件的方式实现的。
要启用Session的功能,需要完成以下步骤:
修改MIDDLEWARE_CLASSES设置,并确定其中包含了'django.contrib.sessions.middleware.SessionMiddleware'。``django-admin.pystartproject``所创建的缺省的settings.py就已经激活了SessionMiddleware。
将'django.contrib.sessions'添加到你的INSTALLED_APPS设置中,并执行manage.pysyncdb以便安装用于存储Session数据的表格。
ChangedinDjango1.0:如果你并未使用数据库存储Session,则此步骤可以忽略;参考配置Session引擎。
Ifyoudon’twanttousesessions,youmightaswellremovetheSessionMiddlewarelinefromMIDDLEWARE_CLASSESand'django.contrib.sessions'fromyourINSTALLED_APPS.It’llsaveyouasmallbitofoverhead.
缺省情况下,Django将Session存储在数据库中(使用模型django.contrib.sessions.models.Session)。尽管这很方便,但在某些情况下,把Session放在其它的地方速度会更快。因此Django允许您通过配置让它将Session数据保存在文件系统或缓冲区中。
要使用基于文件的Session,请将SESSION_ENGINE设置为"django.contrib.sessions.backends.file"。
您可能还需要修改SESSION_FILE_PATH这一设置以便控制Django存储Session文件的位置,缺省情况下,它使用tempfile.gettempdir(),通常是/tmp。
要使用Django的缓冲区系统来保存Session,需要将SESSION_ENGINE设置为"django.contrib.sessions.backends.cache"。您必须确保您已经配置了缓冲区,详情请参考缓冲区文档。
只有在使用Memcached作为缓冲后台时,才能使用基于缓冲区的Session。因为以本地内存作为缓冲后台时,它存储缓冲数据的时间太短了,这样直接访问文件或数据库的速度,要比通过缓冲区访问文件或数据库的速度更快一些。
在开启SessionMiddleware后,每一个HttpRequest对象(Django视图函数的第一个参数)救火有一个session属性,它是一个类字典对象。您可以直接对其读写。
Session对象有以下标准字典函数:
例子:fav_color=request.session['fav_color']
例子:request.session['fav_color']='blue'
例子:delrequest.session['fav_color'].ThisraisesKeyErrorifthegivenkeyisn’talreadyinthesession.
例子:'fav_color'inrequest.session
例子:fav_color=request.session.get('fav_color','red')
NewinDjango1.0:setdefault()和clear()是在这个版本新加的。
从数据库中删除当前的Session数据并且重新生成一个Session键,并将其发送给浏览器。这用于需要确保Session数据无法再从用户浏览器访问时,譬如调用django.contrib.auth.logout()时。
设定检测Cookie以检验用户的浏览器是否支持Cookie。因Cookie的工作方式,在下一次用户请求之前,您都无法得到测试结果。详情参考下面的设置检测Cookie。
判断用户的浏览器是否收到了检测Cookie,并返回True或False。因Cookie的工作方式,您必须在之前的独立请求中调用set_test_cookie()。详情参考下面的设置检测Cookie。
删除检测Cookie,请自己调用此函数以便清除该Cookie。
设定Session的过期时间。您可以提供下述几种形式的值:
如果value是整形,则它表示的是秒。例如,调用request.session.set_expiry(300)会让Session在五分钟后过期。
如果value是datetime或timedelta对象,则Session将会在相应的日期或时间点过期。
如果valueis0,则用户的Session会在浏览器关闭时过期。
如果valueisNone,则Session会使用全局策略来设定过期时间。
获得此Session的过期时间。对于没有自定义过期时间的Session(或在浏览器关闭时过期的Session),此函数返回值与settings.SESSION_COOKIE_AGE相同。
获得此Session的过期时间点。对于没有自定义过期时间的Session(或在浏览器关闭时过期的Session),此函数的返回值等于从现在到时间点settings.SESSION_COOKIE_AGE的秒数。
返回Session是否会在浏览器关闭时过期,返回值为True或False。
您在视图中的任何位置都可以修改request.session,改多少次都行。
直接在request.session上使用Python字符串作为字典的键,这比使用Session对象的方法来得更直接。
在Session字典中,以下划线开始的键,是保留给Django在内部使用的。
不要用一个新的对象覆盖request.session,也不要访问或修改它的属性,它只能作为一个类字典对象使用。
这个简单的视图在用户提交了评价信息后,将变量has_commented设定为True,这样就可以防止用户多次提交评价信息:
defpost_comment(request,new_comment):ifrequest.session.get('has_commented',False):returnHttpResponse("You'vealreadycommented.")c=comments.Comment(comment=new_comment)c.save()request.session['has_commented']=TruereturnHttpResponse('Thanksforyourcomment!')
这个简单的视图让网站的“用户”登录:
deflogin(request):m=Member.objects.get(username=request.POST['username'])ifm.password==request.POST['password']:request.session['member_id']=m.idreturnHttpResponse("You'reloggedin.")else:returnHttpResponse("Yourusernameandpassworddidn'tmatch.")
...与上面的例子相对应的,下面的例子则让用户退出:
deflogout(request):try:delrequest.session['member_id']exceptKeyError:passreturnHttpResponse("You'reloggedout.")
实际上标准的django.contrib.auth.logout()还会多做一些事情从而防止因疏忽造成的数据泄露。它会调用request.session.flush()函数。我们使用这些例子只是演示如何操作Session对象,它可不是一个完整的logout()实现。
为方便起见,Django提供了一种简单的方法来检测用户的浏览器是否支持Cookie。只要在一个请求中调用request.session.set_test_cookie()并在后续请求中调用request.session.test_cookie_worked()即可。注意千万不要在同一次请求中同时调用。
之所以要在两次请求中调用set_test_cookie()和test_cookie_worked()是因为Cookie的工作模式。当您设定了Cookie后,再下一次请求前,都是没有办法知道浏览器是否会接收它的。
另外最好在测试完毕后,使用delete_test_cookie()清除测试用数据。
deflogin(request):ifrequest.method=='POST':ifrequest.session.test_cookie_worked():request.session.delete_test_cookie()returnHttpResponse("You'reloggedin.")else:returnHttpResponse("Pleaseenablecookiesandtryagain.")request.session.set_test_cookie()returnrender_to_response('foo/login_form.html')
有一个API专门用于在视图之外操作Session数据:
fromdjango.contrib.sessions.backends.dbimportSessionStores=SessionStore(session_key='2b1189a188b44ad18c35e113ac6ceead')s['last_login']=datetime.datetime(2005,8,20,13,35,10)s['last_login']datetime.datetime(2005,8,20,13,35,0)s.save()
如果您使用了django.contrib.sessions.backends.db后台,则每一个Session都是一个普通的Django模型。模型Session在文件django/contrib/sessions/models.py中定义。由于它是一个普通的模型,因此您可以使用Django的数据库编程接口直接访问它:
fromdjango.contrib.sessions.modelsimportSessions=Session.objects.get(pk='2b1189a188b44ad18c35e113ac6ceead')s.expire_datedatetime.datetime(2005,8,20,13,35,12)
注意,要获得Session字典,需要调用get_decoded(),这是因为字典是以编码的方式存储的:
s.session_data'KGRwMQpTJ19hdXRoX3VzZXJfaWQnCnAyCkkxCnMuMTExY2ZjODI2Yj...'s.get_decoded(){'user_id':42}
缺省情况下,Django只在Session被修改时才会保存它,即只有字典中的值被修改或删除时:
#Sessionismodified.request.session['foo']='bar'#Sessionismodified.delrequest.session['foo']#Sessionismodified.request.session['foo']={}#Gotcha:SessionisNOTmodified,becausethisalters#request.session['foo']insteadofrequest.session.request.session['foo']['bar']='baz'
对于在上面的最后一个,通过显示地设定Session对象的modified属性,可以通知Session对象它被修改了:
要改变这种行为,可以将SESSION_SAVE_EVERY_REQUEST设定为True。如果SESSION_SAVE_EVERY_REQUEST是True,则Django在每一次独立的请求之后都会保存Session。
注意,只有在创建或修改Session的时候才会送出SessionCookie,如果SESSION_SAVE_EVERY_REQUEST为True,则每次请求都会送出Cookie。
同样地,在送出Cookie时,它的expires部分每次都会被更新。
与浏览器同步的Session和持久的Session?
通过设置SESSION_EXPIRE_AT_BROWSER_CLOSE,您可以控制Session框架使用与浏览器同步的Session或持久的Session。
缺省情况下,SESSION_EXPIRE_AT_BROWSER_CLOSE的值为False,这表示SessionCookie将会保存在用户的浏览器中,直到超过了SESSION_COOKIE_AGE。如果您希望用户不必在每次关闭浏览器后都重新登陆,请使用这种方式。
如果SESSION_EXPIRE_AT_BROWSER_CLOSE设定为True,则Django会使用与浏览器同步的Cookie,即用户关闭浏览器时Cookie就会过期。如果您希望用户每次打开浏览器都必须登录,请使用这种模式。
这个设置具有全局的缺省值,但可以通过调用request.session.set_expiry()为每个Session设定独立的值,相关内容在上述的在视图中使用Session中有所阐述。
注意,Session数据有可能堆积在数据库表格django_session中,Django不提供自动清除它们的功能。它把定期清空Session数据的任务留给了您。
要理解这个问题,想像一下用户使用Session时会发生什么。当用户登录,Django向表格django_session中添加一条记录。每当Session数据变化时,Django会更新这条记录。如果用户手工退出了,Django会删除它。但是,如果用户没有退出,则这条记录永远都不会被删除。
Django提供了一个能够完成清除功能的样例脚本django-admin.pycleanup,它从Session表格中删除那些expire_date已经过期的记录,但是您的应用程序可能会有其它的需求。
一些Django设置可以帮助您控制Session的行为:
缺省值:django.contrib.sessions.backends.db
控制Django在何处保存Session数据,合法的值为:
'django.contrib.sessions.backends.db'
'django.contrib.sessions.backends.file'
'django.contrib.sessions.backends.cache'
如果您使用基于文件的Session存储,则此变量控制着Django存储Session数据的目录。
缺省值:1209600(两周,以秒表示)
SessionCookie的过期时间,以秒表示
SessionCookie的域。如果是要设定跨域的Cookie,可以将其设定为".lawrence.com"的形式,否则请使用None。
Session所使用的Cookie的名称,可根据需要设定。
对于SessionCookie,是否要使用安全模式。如果将此设定为True,则Cookie将会被标记为“安全”,这种情况下,
二、如何在django中使用多个数据库
New in Django 1.2: Please, see the release notes
大多数其他文档都假设使用单一数据库,本文主要讨论如何在 Django中使用多个数据库。使用多个数据库,要增加一些步骤。
使用多数据库的第一步是通过 DATABASES设置要使用的数据库服务。这个设置用于映射数据库别名和特定的联结设置字典,这是 Django定义数据库一贯的手法。字典内部的设置参见 DATABASES文档。
数据库可以使用任何别名,但是 default有特殊意义。当没有选择其他数据库时, Django总是使用别名为 default的数据库。因此,如果你没有定义一个名为 default的数据库时,你应当小心了,在使用数据库前要指定你想用的数据库。
以下是一个定义两个数据库的 settings.py代码片断。定义了一个缺省的 PostgreSQL数据库和一个名为 users的 MySQL数据库:
DATABASES={'default':{'NAME':'app_data','ENGINE':'django.db.backends.postgresql_psycopg2','USER':'postgres_user','PASSWORD':'s3krit'},'users':{'NAME':'user_data','ENGINE':'django.db.backends.mysql','USER':'mysql_user','PASSWORD':'priv4te'}}
如果你尝试访问 DATABASES设置中没有定义的数据库, Django会抛出一个 django.db.utils.ConnectionDoesNotExist异常。
syncdb管理命令一次只操作一个数据库。缺省情况下,它操作 default数据库。但是加上--database参数,你可以让 syncdb同步不同的数据库。所以要同步我们例子中的所有数据库的所有模型可以使用如下命令:
$./manage.py syncdb--database=users
如果你不是同步所有的程序到同一个数据库中,你可定义一个数据库路由来为指定的模型实施特定的控制策略。
如果你要精细地控制同步,那么还有一种方式是修改 sqlall的输出,手工在数据库中执行命令,命令如下:
$./manage.py sqlall sales|./manage.py dbshell
其他操作数据库的 django-admin.py命令与 syncdb类似,他们一次只操作一个数据库,使用--database来控制使用哪个数据库。
使用多数据库最简单的方法是设置一个数据库路由方案。缺省的路由方案确保对象“紧贴”其原本的数据库(例如:一个对象从哪个数据库取得,就保存回哪个数据库)。缺省的路由方案还确保如果一个数据库没有指定,所有的查询都会作用于缺省数据库。
你不必为启动缺省路由方案作任何事,因为它是“开箱即用”的。但是,如果你要执行一些更有趣的数据库分配行为的话,你可以定义并安装你自己的数据库路由。
一个数据库路由是一个类,这个类最多有四个方法:
建议 model对象写操作时使用的数据库。
如果一个数据库操作可以提供对选择数据库有用的附加信息,那么可以通过 hints字典提供。详见下文。
建议 model对象读操作时使用的数据库。
如果一个数据库操作可以提供对选择数据库有用的附加信息,那么可以通过 hints字典提供。详见下文。
allow_relation(obj1, obj2,**hints)
当 obj1和 obj2之间允许有关系时返回 True,不允许时返回 False,或者没有意见时返回 None。这是一个纯粹的验证操作,用于外键和多对多操作中,两个对象的关系是否被允许。
决定 model是否可以和 db为别名的数据库同步。如果可以返回 True,如果不可以返回 False,或者没有意见时返回 None。这个方法用于决定一个给定数据库的模型是否可用。
一个路由不必提供所有这些方法,可以省略其中一个或多个。如果其中一个方法被省略了,那么 Django会在执行相关检查时跳过相应路由。
数据库路由接收的“提示”参数可用于决定哪个数据库应当接收一个给定的请求。
目前,唯一可以提供的提示参数是实例,即一个与读写操作相关的对象的实例。可以是一个已保存的对象的实例,也可以是一个多对多关系中添加的实例。在某些情况下,也可能没有对象的实例可以提供。路由会检查提示实例是否存在,并相应地决定是否改变路由行为。
数据库路由使用 DATABASE_ROUTERS设置来安装。这个设置定义一个类名称列表,每个类定义一个用于主路由(django.db.router)的路由。
主路由用于 Django分配数据库操作。当一个查询想要知道使用哪个数据库时,会提供一个模型和一个提示(如果有的话),并调用主路由。
Django就会按次序尝试每个路由,
直到找到合适的路由建议。如果找不到路由建议就会尝试实例提示的当前的 _state.db。如果没有提供路由提示,或者实例没有当前数据库状态,那么
这个例子仅用于展示路由如何改变数据库的使用。本例有意忽略了一些复杂的东西以便于更好的展示路由是如何工作的。
如果任何一个 myapp中的模型包含与另一个数据库中模型的关系时,本例是无效的。参见跨数据库关系一节中介绍的 Django引用完整性问题。
本例的主/从配置也是有缺陷的:它没有处理复制延时(比如因为把写操作传递给从数据库耗费时间而产生的查询不一致),也没有考虑与数据库使用策略的交互作用。
那么,这个例子有什么用呢?本例仅用于演示一个 myapp存在于 other数据库,所有其他模型之间是主/从关系,且存在于 master、 slave1和 slave2数据库。本例使用了两个路由:
class MyAppRouter(object):"""一个控制 myapp应用中模型的所有数据库操作的路由""" def db_for_read(self, model,**hints):"myapp应用中模型的操作指向'other'" if model._meta.app_label=='myapp': return'other' return None def db_for_write(self, model,**hints):"myapp应用中模型的操作指向'other'" if model._meta.app_label=='myapp': return'other' return None def allow_relation(self, obj1, obj2,**hints):"如果包含 myapp应用中的模型则允许所有关系" if obj1._meta.app_label=='myapp' or obj2._meta.app_label=='myapp': return True return None def allow_syncdb(self, db, model):"确保 myapp应用只存在于'other'数据库" if db=='other': return model._meta.app_label=='myapp' elif model._meta.app_label=='myapp': return False return None class MasterSlaveRouter(object):"""一个设置简单主/从定义的路由""" def db_for_read(self, model,**hints):"所有读操作指向一个随机的从数据库" return random.choice(['slave1','slave2']) def db_for_write(self, model,**hints):"所有写操作指向主数据库" return'master' def allow_relation(self, obj1, obj2,**hints):"允许数据库池中的两个对象间的任何关系" db_list=('master','slave1','slave2') if obj1._state.db in db_list and obj2._state.db in db_list: return True return None def allow_syncdb(self, db, model):"显示地放置所有数据库中的模型" return True
然后在你的设置文件增加如下内容(把 path.to.替换为你定义路由的模型的路径):
DATABASE_ROUTERS= ['path.to.MyAppRouter','path.to.MasterSlaveRouter']
这个设置中,路由的顺序是很重要的,因为查询时是按这个设置中的顺序依次查询的。上例中, MyAppRouter先于MasterSlaveRouter,因此, myapp中的模型就优先于其他模型。如果 DATABASE_ROUTERS设置中两个路由的顺序变换了,那么 MasterSlaveRouter.allow_syncdb()会优先执行。因为 MasterSlaveRouter是包罗万象的,这样就会导致所有模型可以使用所有数据库。
设置好之后让我们来运行一些代码:
>>>#从'credentials'数据库获得数据>>> fred= User.objects.get(username='fred')>>> fred.first_name='Frederick'>>>#保存到'credentials'数据库>>> fred.save()>>>#随机从从数据库获得数据>>> dna= Person.objects.get(name='Douglas Adams')>>>#新对象创建时还没有分配数据库>>> mh= Book(title='Mostly Harmless')>>>#这个赋值会向路由发出请求,并把 mh的数据库设置为与 author对象同样的>>>#数据库>>> mh.author= dna>>>#这会强制'mh'实例使用主数据库...>>> mh.save()>>>#...但如果我们重新获取对象,就会从从数据库中获取>>> mh= Book.objects.get(title='Mostly Harmless')
Django也提供一个可以让你通过代码完全控制数据库使用的 API。手动定义数据库分配优先于路由。
为一个查询集手动选择一个数据库
你可以在查询集“链”中的任何点为查询集选择数据库。我们通过在查询集上调用 using()来得到使用指定数据库的另一个查询集。
using()使用一个参数:你想要运行查询的数据库的别名。例如:
>>>#这会运行在“缺省”数据库上。>>> Author.objects.all()>>>#这同样会运行在“缺省”数据库上。>>> Author.objects.using('default').all()>>>#这会运行在“ other”数据库上。>>> Author.objects.using('other').all()
在使用 Model.save()时加上 using关键字可以指定保存到哪个数据库。
例如,要把一个对象保存到 legacy_users数据库应该这样做:
>>> my_object.save(using='legacy_users')
如果你不定义 using,那么 save()方法会根据路由分配把数据保存到缺省数据库中。
把一个对象从一个数据库移动到另一个数据库
当你已经在一个数据库中保存了一个对象后,你可能会使用 save(using=...)把这个对象移动到另一个数据库中。但是,如果你没有使用恰当的方法,那么可能会出现意想不到的后果。
>>> p= Person(name='Fred')>>> p.save(using='first')#(第一句)>>> p.save(using='second')#(第二名)
在第一名中,一个新的 Person对象被保存到 first数据库中。这时, p还没有一个主键,因此 Django执行了一个INSERT SQL语句。这样就会创建一个主键,并将这个主键分配给 p。
在第二句中,因为 p已经有了一个主键,所以 Django在保存对象时会尝试在新的数据库中使用这个主键。如果 second数据库中没有使用这个主键,那就不会有问题,该对象会复制到新数据库。
然而,如果 p的主键在 second数据库中已经使用过了,那么 second使用这个主键的已存在的对象将会被 p覆盖。
有两种方法可以避免上述情况的发生。第一,你可以清除实例的主键。如果一个对象没有主主键,那么 Django会把它看作一个新对象,在保存到 second数据库中时就不会带来数据的损失:
>>> p= Person(name='Fred')>>> p.save(using='first')>>> p.pk= None#清除主键。>>> p.save(using='second')#写入一个全新的对象。
第二种方法是在 save()方法中使用 force_insert选项来保证 Django执行一个 INSERT SQL:
>>> p= Person(name='Fred')>>> p.save(using='first')>>> p.save(using='second', force_insert=True)
这样可以保证名为 Fred的人员在两个数据库中使用相同的主键。如果在保存到 second数据库时主键已被占用,会抛出一个错误。
缺省情况下,一个现存对象从哪个数据库得到,删除这个对象也会在这个数据库中进行:
>>> u= User.objects.using('legacy_users').get(username='fred')>>> u.delete()#会从 `legacy_users`数据库中删除
通过向 Model.delete()方法传递 using关键字参数可以定义在哪个数据库中删除数据。 using的用法与 save()方法中使用这个参数类似。
例如,假设我们要把一个用户从 legacy_users数据库移动到 new_users数据库可以使用如下命令:
>>> user_obj.save(using='new_users')>>> user_obj.delete(using='legacy_users')
在管理器上使用 db_manager(),可以让管理器访问一个非缺省数据库。
例如,假设你有一个操作数据库的自定义管理器 User.objects.create_user()。
因为 create_user()是一个管理器方法,不是一个查询集,所以你不能
用 User.objects.using('new_users').create_user()。( create_user()方法
只能用于 User.objects管理器,而不能用于,管理器衍生出的查询集。)解决方法是使用 db_manager(),就象下面这样:
User.objects.db_manager('new_users').create_user(...)
db_manager()返回的是绑定到你指定的数据库的管理器的一个副本。
多数据库情况下使用 get_query_set()
如果你在管理器中重载了 get_query_set(),请确保在其父类中也调用了相同的方法(使用 super())或者正确处理管理器中的 _db属性(一个包含要使用的数据库名称的字符串)。
例如,如果你要从 get_query_set方法返回一个自定义查询集类,那么你可以这样做:
class MyManager(models.Manager): def get_query_set(self): qs= CustomQuerySet(self.model) if self._db is not None: qs= qs.using(self._db) return qs
在 Django管理接口中使用多数据库
Django的管理接口没有明显支持多数据库。如果想要支持的话你必须写自定义 ModelAdmin。
三、django如何更改数据库
导读:本篇文章首席CTO笔记来给大家介绍有关django如何更改数据库的相关内容,希望对大家有所帮助,一起来看看吧。
修改setting.py里面的DATABASES元组为
'ENGINE':'django.db.backends.mysql',
'NAME':'books',#你的数据库名称
'USER':'root',#你的数据库用户名
'HOST':'',#你的数据库主机,留空默认为localhost
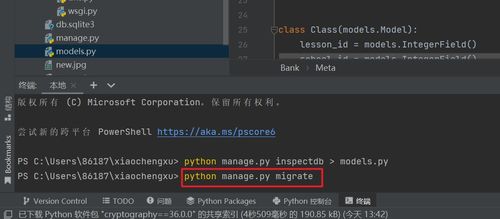
使用pythonmanage.pysqlallbooks显示mysql语法
使用pythonmanage.pysyncdb同步模型中的数据库
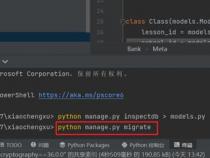
从Javaweb转过来学习django,有些方法逻辑不习惯,直接修改model更新到数据库:执行如下命令即可pythonmanage.pymakemigrationsmyapppythonmanage.pymigrate
djangotestcase单元测试时,如何使用正式数据库,而且能够访问、修改数据库文件,而不是创建临时数据库
string希望被替换的字符或变量
formset是一个困惑的东西。用好了可以简化代码,减少template和view的工作量。不过初学的时候,可以自己直接写html代码更直观些。
formset似乎与数据库并没有直接的关系。查询数据库的class.objects.query里,使用select语句什么都能过滤。当然也可以用get,all,filter等函数,在函数的入口里加入等于的过滤条件,这个过滤比较的简单的。
结语:以上就是首席CTO笔记为大家整理的关于django如何更改数据库的全部内容了,感谢您花时间阅读本站内容,希望对您有所帮助,更多关于django如何更改数据库的相关内容别忘了在本站进行查找喔。