正则表达式的贪婪模式与非贪婪模式
发布时间:2025-05-23 04:44:24 发布人:远客网络

一、正则表达式的贪婪模式与非贪婪模式
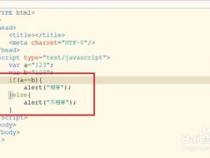
1、作为开始,我们先看下面的正则:
2、我们本来预想上面会匹配得到"witch"和"broom"两个字符串,运行上面的例子,却发现结果只匹配到"witch" and her"broom"一个字符串。
3、之所以出现这个结局,是因为正则的贪婪模式在起作用。
4、首先我们假设自己是正则引擎,来模拟搜索实现的过程。
5、正则引擎先从字符串的第0位开始搜索。
6、总结:在贪婪(默认)模式下,正则引擎尽可能多的重复匹配字符。
7、非贪婪模式和贪婪模式相反,可通过在代表数量的标识符后放置?来开启非贪婪模式,如?、+?甚至是??。
8、我们来看看非贪婪模式.?是怎么运转的:
9、总结:在非贪婪模式下,正则引擎尽可能少的重复匹配字符。
二、正则表达式“或“的使用
正则表达式,又称规则表达式。是计算机科学的一个概念。
正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。许多程序设计语言都支持利用正则表达式进行字符串操作。例如,在Perl中就内建了一个功能强大的正则表达式引擎。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。
正则表达式通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。
检查字符串是否符合正则表达式中的规则,有一次不匹配,则返回false。如:
String reg="[a-zA-Z]\\d?";//次表达式表示字符串的第一位只能是字母,第二位只能是数字或没有boolean flag=str.matches(reg);//返回结果为true。
所谓切割,即是按一定的规则将字符串分割成多个子字符串,如:
String str="zhangsan,lishi,wangwu"。
String reg=",";//表示以逗号作为切割符。
String[] arr=str.split(reg);//返回结果为{“zhangsan”,"lisi","wangwu}。
即将字符串中符合规则的字符替换成指定字符,如:
String str="sfhjhfh136hjasdf73466247fsjha8437482jfjsfh746376"。
str.replaceAll("\\d{3,}","#");//表示将连续出现三个或三个以上的数字替换成“#”。
参考资料来源:百度百科-正则表达式
三、正则表达式
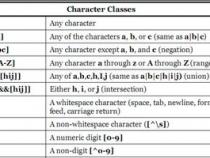
1. \d 任意数字
\w 任意字母数字下划线
\s 空格,制表符,换行符等字符
. 除了换行符任意一个字符
2. [ab5@]表示匹配里面的任意一个字符
[^a]除a外的任意一个字符
[f-k]匹配f到k的任意一个字符
补充:特殊符号被包含在中括号中失去意义,只代表符号本身,^-除外;
标准字符集合除小数点外被包含在中括号中,自定义字符集包含该集合。
如[\d.-+] 匹配:数字小数点+-。
\d{6} 匹配6个数字
{n,m}最少重复n次最多m次
默认贪婪模式即匹配的越多越好,加?非贪婪模式
\d{6}?
\d{6,}最少6次
?匹配0次或1次,相当于{0,1}
+ 表达式至少出现一次,相当于{1,}
* 出现任意次,相当于{0,}
^表示字符开始的位置
^i 匹配字符串开头第一个字符位置
$ 字符串结束的位置
\b 不全是\w
\A\Z分别表示文本开头和结尾
四、分支结构、捕获组、非捕获组
分支结构 | 或
捕获组 () 捕获所匹配的字符,后面跟/1、/2来取匹配的字符
非捕获组(?:)不捕获括号内匹配的字符,有利于减小内存开支。
(?=表达式) 表示后面匹配的表达式,但不包括匹配的字符串
(?<=表达式) 断言自身前面出现的表达式
(?!表达式)自身后面不能出现的表达式
(?<!表达式)断言此位置前面不能匹配的表达式