UniProt数据库使用指南
发布时间:2025-05-22 22:25:52 发布人:远客网络
一、UniProt数据库使用指南
1、在这个信息爆炸的时代,我们如同航船在知识的海洋中探索,如何运用高效的工具筛选出那些对科研工作至关重要的数据,显得尤为重要。在医学、药学和免疫学的探索之旅中,Uniprot数据库,以其卓越的精确度和广泛的应用,成为了我们不可或缺的导航灯塔。今天,让我们一起深入了解如何巧妙利用这个宝藏数据库,以IL-6为例,揭开其神秘面纱。
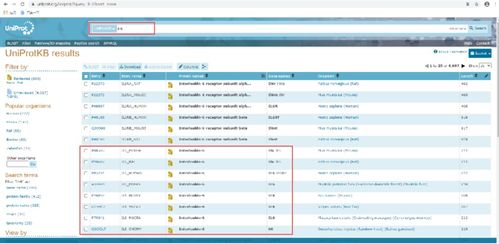
2、首先,登录Uniprot官网(),键入关键词“IL-6”,点击搜索,然后根据研究的物种筛选,即可解锁关于这一关键蛋白的详尽信息。
3、在“Function”模块,你会发现IL-6的基本功能及其在生物学过程中扮演的角色,每一条功能描述后都附有参考文献,如同打开知识宝库的钥匙(Function界面)。接下来,“Names& Taxonomy”板块揭示了它的命名历史、归属物种以及与NCBI和Ensembl基因数据库的连接,点击即可进一步探索(命名和来源种属信息)。
4、深入研究,我们关注实验中的实际应用。在“Expression”部分,Uniprot提供组织和细胞层面的表达谱,帮助我们理解IL-6在体内分布,如在脂肪和淋巴组织中的高表达(表达谱和定位)。同时,“Subcellular location”揭示了IL-6在细胞内的精确位置,如内质网、细胞膜和分泌性,这对于理解实验结果的特异性至关重要。
5、继续探索,我们揭示了蛋白的精细结构——“Topology”部分详细列出了IL-6的胞外区、跨膜区和胞内区,以及其对应的氨基酸序列,这些信息对于选择合适的蛋白产品至关重要(蛋白的拓扑结构)。
6、在“PTM/Processing”部分,Uniprot揭示了IL-6的合成和修饰过程,如剪切、糖基化、脂酰化等,为理解其功能和作用提供了更为深入的视角(序列范围和分子加工)。
7、综上所述,Uniprot数据库犹如一座宝库,为我们揭示了IL-6的生物学功能、命名背景、分子结构和修饰状态,这些关键信息无疑为我们的研究工作提供了有力的支撑。通过有效利用这些数据,我们能够更加自信地驾驭科研的航程,推动科研成果的前行。
二、一文读懂 UniProt 数据库(2023最新版)
1、Uniprot(Universal Protein)是一个集成了蛋白质序列、功能信息以及研究论文索引的蛋白质数据库,它整合了包括EBI( European Bioinformatics Institute)、SIB(the Swiss Institute of Bioinformatics)和PIR(Protein Information Resource)等三大数据库的资源。
2、目前,UniProt主要由以下子库构成:UniParc、UniProtKB、Proteomes和UniRef。其中,UniParc作为数据仓库,为UniProtKB、Proteomes和UniRef提供数据支持。UniProtKB由Swiss-Prot和TrEMBL两个子库构成。Swiss-Prot经过人工验证和注释,是高质量的蛋白质注释数据;而TrEMBL则存储由机器自动翻译和预测的蛋白质序列。
3、Swiss-Prot是一个高质量的、手工注释的、非冗余的数据集,它提供高水平注释和蛋白质序列。Swiss-Prot由Amos Bairoch博士在1986年创建,由瑞士生物信息学研究所开发,随后由欧洲生物信息学研究所的Rolf Apweiler开发。注释主要来自文献中的研究成果和E-value校验过计算分析结果,有质量保证的数据才被加入该数据库。
4、Swiss-Prot的注释使用相关出版物通过搜索数据库进行识别,阅读每篇论文的全文,然后提取信息并将其添加到条目中。科学文献中的注释包括但不限于计算机预测。Swiss-Prot条目的注释中使用了一系列序列分析工具,包括手动检测和评估,计算机预测。这些预测包括翻译后修饰、跨膜结构域和拓扑、信号肽、结构域识别和蛋白质家族分类等。
5、UniProt的查询蛋白质基础操作包括进入官网、切换数据库、输入基因名、uniprot id、物种名等,然后点击进行搜索。新版界面主要由搜索框、搜索结果表和左边过滤选项面板构成。用户可以根据需要过滤搜索结果,例如根据Unprot ID、蛋白质Uniprot名称、蛋白质名称、基因名、物种名、序列长等进行筛选。
6、此外,UniProt还提供了高级搜索、蛋白质 ID转换等功能。高级搜索允许用户根据特定的搜索条件进行搜索,如查询具有蛋白质三维结构的蛋白质列表。蛋白质 ID转换功能可以将UniProtKB AC/ID转换为PDB ID。
7、TrEMBL(翻译的EMBL核苷酸序列数据库)是为了给更多的蛋白质提供自动注释而创建的。在三大核酸数据库中注释的编码序列都会被自动翻译并加入该数据库中。它也包含来自PDB数据库的序列,以及Ensembl、Refeq和CCDS基因预测的序列。
8、UniParc包含来自主要公共可用蛋白质序列数据库的所有蛋白质序列的非冗余数据集。为了避免冗余,UniParc仅将每个唯一序列存储一次,并记录所有更改的历史记录。
9、UniRef(UniProt Reference Clusters)聚类序列可显著减小数据库大小,从而加快序列搜索的速度。UniRef100序列将相同的序列和序列片段合并到一个UniRef条目中,用于显示代表性蛋白质的序列。
10、最新版的UniProt整合了深度学习模型预测的结果,包括DeepMind团队构建的AlphaFold2预测的蛋白质三维结构,以及Google Brain团队构建的ProtNLM预测的蛋白质序列注释。
三、uniprot蛋白质序列数据库由哪几部分组成各有什么特点
将PIR、SWISS-PROT和TrEMBL3个蛋白质数据库统一-起来组建而成,包含3个部分:
,这是蛋白质序列、功能、分类、交叉引用等蛋白质知识库,记录经过人工筛选和注释;
数据库,将密切相关的蛋白质序列组合到一条记录中,以便提高搜索速度;目前,根据序列相似程度形成3个子库,即UniRef100、UniRef90和UniRef50;
收录所有蛋白质序列。用户可以通过文本查询数据库,可以利用BLAST程序搜索数据库,也可以直接通过FTP下载数据。