JavaScript 正则表达式匹配汉字
发布时间:2025-05-22 16:10:54 发布人:远客网络

一、JavaScript 正则表达式匹配汉字
在JavaScript中,正则表达式匹配汉字的传统方法是`/[\u4e00-\u9fa5]/`,这个正则从1992年至1999年间准确匹配了Unicode 1.0.1版本收录的中日韩统一表意文字。然而,随着Unicode的更新,这个正则不再覆盖所有新增的汉字。在2018年及以后,我们需要更现代的方法来处理汉字匹配。
Unicode 2018年引入的`\p`和`\u`标志提供了解决方案。`\p{Unified_Ideograph}`匹配所有统一表意文字,它根据字符的Unicode属性进行匹配,无需关注具体编码范围,开发者无需关注汉字的具体Unicode码点。这种方法更便于维护,因为它的底层实现由运行时依赖的Unicode版本决定。
`\p{Ideographic}`虽然也用于匹配汉字,但它包括了额外的非汉字字符,如西夏文、女书和兼容性字符,使用时需要谨慎。`Script=Han`属性则用于匹配汉文字符集,包括部首和符号,与汉字的概念有所混淆。
在JavaScript中,为了兼容性,Chrome 64及以上版本支持`\p`属性,而较旧版本可能需要借助`@babel/env`或`babel-plugin-proposal-unicode-property-regex`进行转译。`pattern`属性在HTML中使用时,需要施加`unicode`标志,以确保匹配所有Unicode字符。
总结来说,为了匹配最新的Unicode汉字,建议使用`\p{Unified_Ideograph}`或通过转译确保正则表达式的兼容性。参考了Unicode 10.0.0的详细信息和相关标准,如UAX#44和#24,以及HTML和Angular的规范。
二、UTF-8的正则表达式匹配的汉字如何
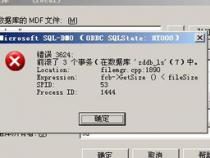
1、为了判断输入内容是否包含非法字符,我们可以通过使用正则表达式来进行验证。例如,以下代码用于匹配UTF-8编码的中文字符、字母、数字和下划线:
2、如果(!preg_match('/^[\u4e00-\u9fa5a-zA-Z0-9_]+$/U',$str)))
3、这段代码表示如果输入的字符串$str包含非法字符,则代码将输出“输入的结构包含非法字符”。否则,输出“输入的结构是完全合法的”。确保正则表达式与UTF-8编码兼容。
4、在JavaScript中,判断字符串是否全部为中文也是非常简单。例如:
5、如果(/^[\u4e00-\u9fa5]+$/。test(STR)){alert("所有字符串都是中文")}否则{alert("字符串不全是中文")}
6、在PHP中,我们需要使用正则表达式来匹配中文字符,例如:
7、如果(preg_match('/^[\x{4e00}-\x{9fa5}]+$/U',$str)){print("所有字符串都是中文")}否则{print("字符串不全是中文")}
8、对于PHP的规则,`\x{4e00}-\x{9fa5}`表示字符和字符集的概念。当表示一个16进制数时,需要注意1-2位或4位的表示方式,并确保在使用十六进制时正确添加括号,同时与`U`修饰符一起使用以确保兼容性。
9、在实际应用中,正确使用正则表达式可以准确判断输入内容是否包含非法字符。在PHP中,我们需要考虑到十六进制表示、字符集范围以及修饰符的正确使用,以确保表达式的正确性和兼容性。
10、为了验证上述正则表达式的功能,可以使用以下测试代码(保存为.php文件):
11、如果($action='装饰'){$str=$_POST['dir'];如果(!preg_match('/[\xA1-\xFFa-zA-Z0-9_]+$/U',$str))GB2312汉字字母数字下划线的正则表达式如果(!preg_match('/^[\x{4e00}-\x{9fa5}a-zA-Z0-9_]+$/U',$str))UTF-8中文字符的字母数字下划线的正则表达式{echo'输入的结构包含非法字符';}其他{echo'输入的结构是完全合法的,通过!'}}
12、通过上述示例和测试代码,我们可以理解如何在PHP中使用正则表达式来匹配UTF-8编码的中文字符。希望对您有所帮助。
三、求一去乱码、汉字的正则表达式
\0n带有八进制值 0的字符 n(0<= n<= 7)
\0nn带有八进制值 0的字符 nn(0<= n<= 7)
\0mnn带有八进制值 0的字符 mnn(0<= m<= 3、0<= n<= 7)
\xhh带有十六进制值 0x的字符 hh
\uhhhh带有十六进制值 0x的字符 hhhh
\t制表符('\u0009')
\n新行(换行)符('\u000A')
\r回车符('\u000D')
\f换页符('\u000C')
\a报警(bell)符('\u0007')
\e转义符('\u001B')
[^abc]任何字符,除了 a、b或 c(否定)
[a-zA-Z] a到 z或 A到 Z,两头的字母包括在内(范围)
[a-d[m-p]] a到 d或 m到 p:[a-dm-p](并集)
[a-z&&[^bc]] a到 z,除了 b和 c:[ad-z](减去)
[a-z&&[^m-p]] a到 z,而非 m到 p:[a-lq-z](减去)
.任何字符(与行结束符可能匹配也可能不匹配)
\s空白字符:[\t\n\x0B\f\r]
\p{Lower}小写字母字符:[a-z]
\p{Upper}大写字母字符:[A-Z]
\p{ASCII}所有 ASCII:[\x00-\x7F]
\p{Alpha}字母字符:[\p{Lower}\p{Upper}]
\p{Digit}十进制数字:[0-9]
\p{Alnum}字母数字字符:[\p{Alpha}\p{Digit}]
\p{Punct}标点符号:!"#$%&'()*+,-./:;<=>?@[\]^_`{|}~
\p{Graph}可见字符:[\p{Alnum}\p{Punct}]
\p{Print}可打印字符:[\p{Graph}\x20]
\p{Blank}空格或制表符:[\t]
\p{Cntrl}控制字符:[\x00-\x1F\x7F]
\p{XDigit}十六进制数字:[0-9a-fA-F]
\p{Space}空白字符:[\t\n\x0B\f\r]
java.lang.Character类(简单的 java字符类型)
\p{javaLowerCase}等效于 java.lang.Character.isLowerCase()
\p{javaUpperCase}等效于 java.lang.Character.isUpperCase()
\p{javaWhitespace}等效于 java.lang.Character.isWhitespace()
\p{javaMirrored}等效于 java.lang.Character.isMirrored()
\p{InGreek} Greek块(简单块)中的字符
\p{Lu}大写字母(简单类别)
\P{InGreek}所有字符,Greek块中的除外(否定)
[\p{L}&&[^\p{Lu}]]所有字母,大写字母除外(减去)
\Z输入的结尾,仅用于最后的结束符(如果有的话)
X{n,m} X,至少 n次,但是不超过 m次
X{n,m}? X,至少 n次,但是不超过 m次
X{n,m}+ X,至少 n次,但是不超过 m次
\ Nothing,但是引用以下字符
\Q Nothing,但是引用所有字符,直到\E
\E Nothing,但是结束从\Q开始的引用
(?idmsux-idmsux) Nothing,但是将匹配标志由 on转为 off
(?idmsux-idmsux:X) X,作为带有给定标志 on- off的非捕获组
(?=X) X,通过零宽度的正 lookahead
(?!X) X,通过零宽度的负 lookahead
(?<=X) X,通过零宽度的正 lookbehind
(?<!X) X,通过零宽度的负 lookbehind
(?>X) X,作为独立的非捕获组
--------------------------------------------------------------------------------
反斜线字符('\')用于引用转义构造,如上表所定义的,同时还用于引用其他将被解释为非转义构造的字符。因此,表达式\\与单个反斜线匹配,而\{与左括号匹配。
在不表示转义构造的任何字母字符前使用反斜线都是错误的;它们是为将来扩展正则表达式语言保留的。可以在非字母字符前使用反斜线,不管该字符是否非转义构造的一部分。
根据 Java Language Specification的要求,Java源代码的字符串中的反斜线被解释为 Unicode转义或其他字符转义。因此必须在字符串字面值中使用两个反斜线,表示正则表达式受到保护,不被 Java字节码编译器解释。例如,当解释为正则表达式时,字符串字面值"\b"与单个退格字符匹配,而"\\b"与单词边界匹配。字符串字面值"\(hello\)"是非法的,将导致编译时错误;要与字符串(hello)匹配,必须使用字符串字面值"\\(hello\\)"。
字符类可以出现在其他字符类中,并且可以包含并集运算符(隐式)和交集运算符(&&)。并集运算符表示至少包含其某个操作数类中所有字符的类。交集运算符表示包含同时位于其两个操作数类中所有字符的类。
字符类运算符的优先级如下所示,按从最高到最低的顺序排列:
注意,元字符的不同集合实际上位于字符类的内部,而非字符类的外部。例如,正则表达式.在字符类内部就失去了其特殊意义,而表达式-变成了形成元字符的范围。
行结束符是一个或两个字符的序列,标记输入字符序列的行结尾。以下代码被识别为行结束符:
新行(换行)符('\n')、
后面紧跟新行符的回车符("\r\n")、
单独的回车符('\r')、
下一行字符('\u0085')、
行分隔符('\u2028')或
如果激活 UNIX_LINES模式,则新行符是惟一识别的行结束符。
如果未指定 DOTALL标志,则正则表达式.可以与任何字符(行结束符除外)匹配。
默认情况下,正则表达式 ^和$忽略行结束符,仅分别与整个输入序列的开头和结尾匹配。如果激活 MULTILINE模式,则 ^在输入的开头和行结束符之后(输入的结尾)才发生匹配。处于 MULTILINE模式中时,$仅在行结束符之前或输入序列的结尾处匹配。
捕获组可以通过从左到右计算其开括号来编号。例如,在表达式((A)(B(C)))中,存在四个这样的组:
之所以这样命名捕获组是因为在匹配中,保存了与这些组匹配的输入序列的每个子序列。捕获的子序列稍后可以通过 Back引用在表达式中使用,也可以在匹配操作完成后从匹配器检索。
与组关联的捕获输入始终是与组最近匹配的子序列。如果由于量化的缘故再次计算了组,则在第二次计算失败时将保留其以前捕获的值(如果有的话)例如,将字符串"aba"与表达式(a(b)?)+相匹配,会将第二组设置为"b"。在每个匹配的开头,所有捕获的输入都会被丢弃。
以(?)开头的组是纯的非捕获组,它不捕获文本,也不针对组合计进行计数。