java中hash函数都有什么用啊
发布时间:2025-05-22 15:02:01 发布人:远客网络
一、java中hash函数都有什么用啊
1、Hash,一般翻译做"散列",也有直接音译为"哈希"的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。
2、简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
3、HASH主要用于信息安全领域中加密算法,他把一些不同长度的信息转化成杂乱的128位的编码里,叫做HASH值.也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系
4、了解了hash基本定义,就不能不提到一些著名的hash算法,MD5和 SHA1可以说是目前应用最广泛的Hash算法,而它们都是以 MD4为基础设计的。那么他们都是什么意思呢?
5、MD4(RFC 1320)是 MIT的 Ronald L. Rivest在 1990年设计的,MD是 Message Digest的缩写。它适用在32位字长的处理器上用高速软件实现--它是基于 32位操作数的位操作来实现的。
6、MD5(RFC 1321)是 Rivest于1991年对MD4的改进版本。它对输入仍以512位分组,其输出是4个32位字的级联,与 MD4相同。MD5比MD4来得复杂,并且速度较之要慢一点,但更安全,在抗分析和抗差分方面表现更好
7、SHA1是由NIST NSA设计为同DSA一起使用的,它对长度小于264的输入,产生长度为160bit的散列值,因此抗穷举(brute-force)性更好。SHA-1设计时基于和MD4相同原理,并且模仿了该算法。
二、java jdk中默认的hash函数是什么
hash是Object的一个方法 Object.hashCode();返回值是int类型
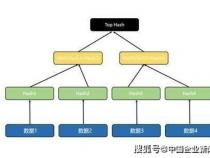
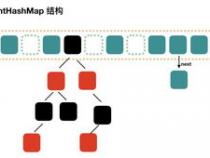
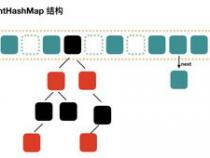
HashMap、HashTable、HashSet,所以涉及到使用Hash值进行优化存储的地方,都会用到HashCode。HashCode是Key,这种计算为提高计算的性能。想想看,一般来说,数组算是比较快的集合类了吧,直接用index定位元素,简直就是O(1)的级别。但是添加元素就不这么乐观了。但是使用hash类的集合,添加元素,移动的元素少,只影响一小块,并且查找元素,由于hash值已经进行了定位分组,所以也会大大缩小涉及面,快速定位。
A、等幂性。不管执行多少次获取Hash值的操作,只要对象不变,那么Hash值是固定的。如果第一次取跟第N次取不一样,那就用起来很麻烦,需要记录当前是第几次操作,这种需要记录状态的事情,可不是什么好事。
B、对等性。若两个对象equal方法返回为true,则其hash值也应该是一样的。举例说明:若你将objA作为key存入HashMap中,然后new了一个objB。在你看来objB和objA是一个东西(因为他们equal),但是使用objB到hashMap中却取不出来东西。
C、互异性。若两个对象equal方法返回为false,则其hash值最好也是不同的,但这个不是必须的,只是这样做会提高hash类操作的性能(碰撞几率低)。
A、简单计算就是组成成员的hash值直接相加即可。比如ObjectA有三个属性,propA、propB和propC,最直接的计算方式就是propA.hashcode+propB.hashcode+propC.hashcode。
B、但是如果遇到有顺序相关的怎么办?比如String类型是由char数组组成,并且这些数组是有顺序的。如果使用第一种计算方法,则“ABCD”和“BCDA”就会产生同样的hashCode,那么怎么办呢?最直接想到的办法就是加权,不同的index加不同的权值,这个权值的确定最直接的方法就是某个常数值的几次幂。比如为String的计算hash值为K^0*A.hashCode+K^1*B.hashCode+K^2*C.hashCode+K^3*D.hashCode。K的选择也有说法,最好不要是偶数,因为偶数的相乘会造成信息的丢失(乘以2就是左移1位,一旦溢出就会造成信息的丢失,这种计算会造成溢出后的值与某个看似不相关的数值得到的结果是一样的),所以最好是奇数,在这一点上比较推荐使用7,因为7=8-1=2^3-1,这样计算的时候,直接左移几位再进行一次普通的加减法即可(Java中常用的是31(32-1=2^5-1))。
三、java中hashset和hashmap 有什么特点。
1、HashSet实现了Set接口,它不允许集合中有重复的值,当我们提到HashSet时,第一件事情就是在将对象存储在HashSet之前,要先确保对象重写equals()和hashCode()方法,这样才能比较对象的值是否相等,以确保set中没有储存相等的对象。如果我们没有重写这两个方法,将会使用这个方法的默认实现。
2、public boolean add(Object o)方法用来在Set中添加元素,当元素值重复时则会立即返回false,如果成功添加的话会返回true。
3、HashMap实现了Map接口,Map接口对键值对进行映射。Map中不允许重复的键。Map接口有两个基本的实现,HashMap和TreeMap。TreeMap保存了对象的排列次序,而HashMap则不能。HashMap允许键和值为null。HashMap是非synchronized的,但collection框架提供方法能保证HashMap synchronized,这样多个线程同时访问HashMap时,能保证只有一个线程更改Map。
4、public Object put(Object Key,Object value)方法用来将元素添加到map中。
5、你可以阅读这篇文章看看HashMap的工作原理,以及这篇文章看看HashMap和HashTable的区别。
6、HashMap实现了Map接口 HashSet实现了Set接口
7、HashMap储存键值对 HashSet仅仅存储对象
8、使用put()方法将元素放入map中使用add()方法将元素放入set中
9、HashMap中使用键对象来计算hashcode值 HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false
10、HashMap比较快,因为是使用唯一的键来获取对象 HashSet较HashMap来说比较慢