java里set list 为什么能遍历集合
发布时间:2025-05-22 11:36:46 发布人:远客网络
一、java里set list 为什么能遍历集合
1、list和set集合是java中最常见的两种数据结构,都是Collection的子集,今天就简单的说说他们两者的遍历以及相互转化吧。
2、 public static void main(String[] args){
3、 List<String> list= new ArrayList<String>();
4、 list.add("c");//可添加重复数据
5、 for(Iterator<String> iterator= list.iterator();iterator.hasNext();){
6、 String value= iterator.next();
7、 for(int i=0;i<list.size();i++){
8、 System.out.println(list.get(i));
9、分析一下这三种遍历吧,第一种迭代器的遍历,执行过程中会进行数据锁定,性能上是安全的,效率较低;
10、第二种,是java新语法,增强型for循环,其中内部也是调用了迭代器;
11、第三种,直接使用取数组的方式,效率最快,但会有多线程安全问题。
12、ArrayList底层是采用数组来保存数据的,对于访问数组里的数据来说,直接采用数组索引当然是最快的了,相当于直接从内存读取数据,其他的两种迭代方式,实际上都是一种,即iterator,foreach包装了一下;iterator遍历最终还是要通过索引来访问数据,源码中对应的get方法了。
13、Set的遍历和List类似,由于set没有get方法,所有第三种是不可以的;
14、总结:综合考虑使用第二种,增强型for循环就可以
15、这个需求一般也不多,直接上代码吧:
16、* List和Set的转化(Set转化成List)
17、public static<T> List<T> SetToList(Set<T> set){
18、List<T> list= new ArrayList<>();
19、使用泛型实现。不过值得注意的是,list转化成set会丢失数据,重复数据会丢失。
二、java中对集合对象list的几种循环访问总结
List一共有三种遍历方法,如下:
publicstaticvoidmain(String[]args){
List<Integer>list=newArrayList<>();
for(inti=0,size=list.size();i<size;i++){
System.out.println(list.get(i));
Iterator<Integer>it=list.iterator();
System.out.println(it.next());
}
数据元素是怎样在内存中存放的?
数据元素是怎样在内存中存放的?
1、顺序存储,Random Access(Direct Access):
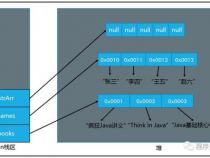
这种方式,相邻的数据元素存放于相邻的内存地址中,整块内存地址是连续的。可以根据元素的位置直接计算出内存地址,直接进行读取。读取一个特定位置元素的平均时间复杂度为O(1)。正常来说,只有基于数组实现的集合,才有这种特性。Java中以ArrayList为代表。
2、链式存储,Sequential Access:
这种方式,每一个数据元素,在内存中都不要求处于相邻的位置,每个数据元素包含它下一个元素的内存地址。不可以根据元素的位置直接计算出内存地址,只能按顺序读取元素。读取一个特定位置元素的平均时间复杂度为O(n)。主要以链表为代表。Java中以LinkedList为代表。
每个遍历方法的实现原理是什么?
1、传统的for循环遍历,基于计数器的:
遍历者自己在集合外部维护一个计数器,然后依次读取每一个位置的元素,当读取到最后一个元素后,停止。主要就是需要按元素的位置来读取元素。
每一个具体实现的数据集合,一般都需要提供相应的Iterator。相比于传统for循环,Iterator取缔了显式的遍历计数器。所以基于顺序存储集合的Iterator可以直接按位置访问数据。而基于链式存储集合的Iterator,正常的实现,都是需要保存当前遍历的位置。然后根据当前位置来向前或者向后移动指针。
根据反编译的字节码可以发现,foreach内部也是采用了Iterator的方式实现,只不过Java编译器帮我们生成了这些代码。
1、传统的for循环遍历,基于计数器的:
顺序存储:读取性能比较高。适用于遍历顺序存储集合。
链式存储:时间复杂度太大,不适用于遍历链式存储的集合。
顺序存储:如果不是太在意时间,推荐选择此方式,毕竟代码更加简洁,也防止了Off-By-One的问题。
链式存储:意义就重大了,平均时间复杂度降为O(n),还是挺诱人的,所以推荐此种遍历方式。
foreach只是让代码更加简洁了,但是他有一些缺点,就是遍历过程中不能操作数据集合(删除等),所以有些场合不使用。而且它本身就是基于Iterator实现的,但是由于类型转换的问题,所以会比直接使用Iterator慢一点,但是还好,时间复杂度都是一样的。所以怎么选择,参考上面两种方式,做一个折中的选择。
三、java中的集合有几种
集合类是放在java.util.*;这个包里。集合类存放的都是对象的引用,而非对象本身,为了说起来方便些,我们称集合中的对象就是指集合中对象的引用(reference)。引用的概念大家不会忘了吧,在前边我们讲数据类型时讲的。
集合类型主要有3种:set(集)、list(列表)、map(映射)和Queue(队列)。//队列为jdk5中的加上的
集(set)是最简单的一种集合,它的对象不按特定方式排序,只是简单的把对象加入集合中,就像往口袋里放东西。对集中成员的访问和操作是通过集中对象的引用进行的,所以集中不能有重复对象。我们知道数学上的集合也是Set这个,集合里面一定是没有重复的元素的。
列表(List)的主要特征是其对象以线性方式存储,没有特定顺序,只有一个开头和一个结尾,当然,它与根本没有顺序的Set是不同的。它是链表嘛,一条链肯定有顺序这个顺序就不一定了。
映射(Map),这个在java里不是地图的意思,其实地图也是映射哈。它里面的东西是键-值对(key-value)出现的,键值对是什么呢?举个例子,比如我们查字典,用部首查字法。目录那个字就是键,这个字的解释就是值。键和值成对出现。这样说可以理解吧。这也是很常用的数据结构哦。
在jdk5.0以前,通常的实现方式是使用java.util.List集合来模仿Queue。Queue的概念通过把对象添加(称为enqueuing的操作)到List的尾部(即Queue的后部)并通过从List的头部(即Queue的前部)提取对象而从 List中移除(称为dequeuing的操作)来模拟。你需要执行先进先出的动作时可以直接使用Queue接口就可以了。
这4个东西,有时候功能还不太完善,需要有些子类继承它的特性。Set的子接口有TreeSet,SortedSet,List的有ArrayList等,Map里有HashMap,HashTable等,Queue里面有BlockingQueue等。我们来看看例子吧:
public static void main(String[] args){
Set set= new HashSet();//HashSet是Set的子接口
public static void main(String[] args){
public static void main(String[] args) throws java.io.FileNotFoundException{
Map word_count_map= new HashMap();
FileReader reader= new FileReader(args[0]);
Iterator words= new WordStreamIterator(reader);
String word=(String) words.next();
String word_lowercase= word.toLowerCase();
Integer frequency=(Integer)word_count_map.get(word_lowercase);
int value= frequency.intValue();
frequency= new Integer(value+ 1);}
word_count_map.put(word_lowercase, frequency);
System.out.println(word_count_map);
public Queue<String> q;//发现了一个奇怪的语法,这个尖括号是泛型声明
public QueueTester(){q= new LinkedList<String>();}
public void testFIFO(PrintStream out) throws IOException{
public static void main(String[] args){
QueueTester tester= new QueueTester();
try{ tester.testFIFO(System.out);