jszip压缩文件夹教你JavaScript在线解压ZIP文件
发布时间:2025-05-22 11:26:40 发布人:远客网络
一、jszip压缩文件夹教你JavaScript在线解压ZIP文件
相信大家对 ZIP文件都不会陌生,当你要打开本地的 ZIP文件时,你就需要先安装支持解压 ZIP文件的解压软件。但如果预解压的 ZIP文件在服务器上,我们应该如何处理呢?最简单的一种方案就是把文件下载到本地,然后使用支持 ZIP格式的解压软件进行解压。那么能不能在线解压 ZIP文件呢?答案是可以的,接下来阿宝哥将介绍浏览器解压和服务器解压两种在线解压 ZIP文件的方案。
在介绍在线解压 ZIP文件的两种方案前,我们先来简单了解一下 ZIP文件格式。
ZIP文件格式是一种数据压缩和文档储存的文件格式,原名 Deflate,发明者为菲尔·卡茨(Phil Katz),他于 1989年 1月公布了该格式的资料。ZIP通常使用后缀名“.zip”,它的 MIME格式为“application/zip”。目前,ZIP格式属于几种主流的压缩格式之一,其竞争者包括RAR格式以及开放源码的 7z格式。
ZIP是一种相当简单的分别压缩每个文件的存档格式,分别压缩文件允许不必读取另外的数据而检索独立的文件。理论上,这种格式允许对不同的文件使用不同的算法。然而,在实际上,ZIP大多数都是在使用卡茨(Katz)的 DEFLATE算法。
简单介绍完 ZIP格式,接下来阿宝哥先来介绍基于 JSZip这个库的浏览器解压方案。
关注「全栈修仙之路」阅读阿宝哥原创的 4本免费电子书(累计下载 3万)及 11篇 Vue 3进阶系列教程。
JSZip这是一个用于创建、读取和编辑.zip文件的 JavaScript库,该库支持大多数浏览器,具体的兼容性如下图所示:
其实有了 JSZip这个库的帮助,要实现浏览器端在线解压 ZIP文件的功能并不难。因为官方已经为我们提供了解压本地文件、解压远程文件和生成 ZIP文件的完整示例。好的,废话不多说,下面我们来一步步实现在线解压 ZIP文件的功能。
浏览器端在线解压 ZIP文件的功能,可以拆分为下载 ZIP文件、解析 ZIP文件和展示 ZIP文件 3个小功能。考虑到功能复用性,阿宝哥把下载 ZIP文件和解析 ZIP文件的逻辑封装在 ExeJSZip类中:
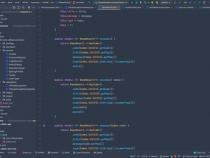
class ExeJSZip{//用于获取url地址对应的文件内容 getBinaryContent(url, progressFn=()=>{}){ return new Promise((resolve, reject)=>{ if(typeof url!=="string"||!/https?:/.test(url)) reject(new Error("url参数不合法")); JSZipUtils.getBinaryContent(url,{// JSZipUtils来自于jszip-utils这个库 progress: progressFn, callback:(err, data)=>{ if(err){ reject(err);} else{ resolve(data);}},});});}//遍历Zip文件 async iterateZipFile(data, iterationFn){ if(typeof iterationFn!=="function"){ throw new Error("iterationFn不是函数类型");} let zip; try{ zip= await JSZip.loadAsync(data);// JSZip来自于jszip这个库 zip.forEach(iterationFn); return zip;} catch(error){ throw new error();}}}2.2在线解压 ZIP文件
利用 ExeJSZip类的实例,我们就可以很容易实现在线解压 ZIP文件的功能:
利用 ExeJSZip类的实例,我们就可以很容易实现在线解压 ZIP文件的功能:
const zipUrlEle= document.querySelector("#zipUrl");const statusEle= document.querySelector("#status");const fileList= document.querySelector("#fileList");const exeJSZip= new ExeJSZip();//执行在线解压操作async function unzipOnline(){ fileList.innerHTML=""; statusEle.innerText="开始下载文件..."; const data= await exeJSZip.getBinaryContent( zipUrlEle.value, handleProgress); let items=""; await exeJSZip.iterateZipFile(data,(relativePath, zipEntry)=>{ items= `${zipEntry.name}`;}); statusEle.innerText="ZIP文件解压成功"; fileList.innerHTML= items;}//处理下载进度function handleProgress(progressData){ const{ percent, loaded, total}= progressData; if(loaded=== total){ statusEle.innerText="文件已下载,努力解压中";}
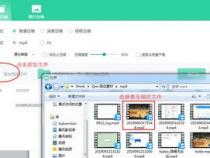
好了,在浏览器端如何通过 JSZip这个库来实现在线解压 ZIP文件的功能已经介绍完了,我们来看一下以上示例的运行结果:
好了,在浏览器端如何通过 JSZip这个库来实现在线解压 ZIP文件的功能已经介绍完了,我们来看一下以上示例的运行结果:
现在我们已经可以在线解压 ZIP文件了,这时有的小伙伴可能会问,能否预览解压后的文件呢?答案是可以的,因为 JSZip这个库为我们提供了 file API,通过这个 API我们就可以读取指定文件中的内容。比如这样使用 zip.file("amount.txt").async("arraybuffer"),之后我们就可以执行对应的操作来实现文件预览的功能。
需要注意的是,基于 JSZip的方案并不是完美的,它存在一些限制。比如它不支持解压加密的 ZIP文件,当解压较大的文件时,在 IE 10以下的浏览器可能会出现闪退问题。此外,它还有一些其它的限制,这里阿宝哥就不详细说明了。感兴趣的小伙伴,可以阅读 Limitations of JSZip文章中的相关内容。
既然浏览器解压方案存在一些弊端,特别是在线解压大文件的情形,要解决该问题,我们可以考虑使用服务器解压方案。
服务器解压方案就是允许用户通过文件 ID或文件名进行在线解压,接下来阿宝哥将基于 koa和 node-stream-zip这两个库来介绍如何实现服务器在线解压 ZIP文件的功能。如果你对 koa还不了解的话,建议你先大致阅读一下 koa的官方文档。
const path= require("path");const Koa= require("koa");const cors= require("@koa/cors");const Router= require("@koa/router");const StreamZip= require("node-stream-zip");const app= new Koa();const router= new Router();const ZIP_HOME= path.join(__dirname,"zip");// ZIP文件的根目录const UnzipCaches= new Map();//保存已解压的文件信息router.get("/", async(ctx)=>{ ctx.body="服务端在线解压ZIP文件示例(阿宝哥)";});//注册中间件app.use(cors());app.use(router.routes()).use(router.allowedMethods());app.listen(3000,()=>{ console.log("app starting at port 3000");});
在以上代码中,我们使用了@koa/cors和@koa/router两个中间件并创建了一个简单的 Koa应用程序。基于上述的代码,我们来注册一个用于处理在线解压指定文件名的路由。
在以上代码中,我们使用了@koa/cors和@koa/router两个中间件并创建了一个简单的 Koa应用程序。基于上述的代码,我们来注册一个用于处理在线解压指定文件名的路由。
router.get("/unzip/:name", async(ctx)=>{ const fileName= ctx.params.name; let filteredEntries; try{ if(UnzipCaches.has(fileName)){//优先从缓存中获取 filteredEntries= UnzipCaches.get(fileName);} else{ const zip= new StreamZip.async({ file: path.join(ZIP_HOME, fileName)}); const entries= await zip.entries(); filteredEntries= Object.values(entries).map((entry)=>{ return{ name: entry.name, size: entry.size, dir: entry.isDirectory,};}); await zip.close(); UnzipCaches.set(fileName, filteredEntries);} ctx.body={ status:"success", entries: filteredEntries,};} catch(error){ ctx.body={ status:"error", msg: `在线解压${fileName}文件失败`,};}});
在以上代码中,我们通过 ZIP_HOME和 fileName获得文件的最终路径,然后使用 StreamZip对象来执行解压操作。为了避免重复执行解压操作,阿宝哥定义了一个 UnzipCaches缓存对象,用来保存已解压的文件信息。定义好上述路由,下面我们来验证一下对应的功能。
在以上代码中,我们通过 ZIP_HOME和 fileName获得文件的最终路径,然后使用 StreamZip对象来执行解压操作。为了避免重复执行解压操作,阿宝哥定义了一个 UnzipCaches缓存对象,用来保存已解压的文件信息。定义好上述路由,下面我们来验证一下对应的功能。
const fileList= document.querySelector("#fileList");const fileNameEle= document.querySelector("#fileName");const request= axios.create({ baseURL:"", timeout: 10000,});async function unzipOnline(){ const fileName= fileNameEle.value; if(!fileName) return; const response= await request.get(`unzip/${fileName}`); if(response.data&& response.data.status==="success"){ const entries= response.data.entries; let items=""; entries.forEach((zipEntry)=>{ items= `${ zipEntry.name}`;}); fileList.innerHTML= items;}}
以上示例成功运行后的结果如下图所示:
以上示例成功运行后的结果如下图所示:
现在我们已经实现根据文件名解压指定 ZIP文件,那么我们可以预览压缩文件中指定路径的文件么?答案也是可以的,利用 zip对象提供的 entryData(entry: string| ZipEntry): Promise方法就可以读取指定路径下文件的内容。
router.get("/unzip/:name/entry", async(ctx)=>{ const fileName= ctx.params.name;// ZIP压缩文件名 const entryPath= ctx.query.path;//文件的路径 try{ const zip= new StreamZip.async({ file: path.join(ZIP_HOME, fileName)}); const entryData= await zip.entryData(entryPath); await zip.close(); ctx.body={ status:"success", entryData: entryData,};} catch(error){ ctx.body={ status:"error", msg: `读取${fileName}中${entryPath}文件失败`,};}});
在以上代码中,我们通过 zip.entryData方法来读取指定路径的文件内容,它返回的是一个 Buffer对象。当前端接收到该数据时,还需要把接收到的 Buffer对象转换为 ArrayBuffer对象,对应的处理方式如下所示:
在以上代码中,我们通过 zip.entryData方法来读取指定路径的文件内容,它返回的是一个 Buffer对象。当前端接收到该数据时,还需要把接收到的 Buffer对象转换为 ArrayBuffer对象,对应的处理方式如下所示:
function toArrayBuffer(buf){ let ab= new ArrayBuffer(buf.length); let view= new Uint8Array(ab); for(let i= 0; i< buf.length; i){ view[i]= buf[i];} return ab;}
定义完 toArrayBuffer函数之后,我们就可以通过调用 app.js定义的 API来实现预览功能,具体的代码如下所示:
定义完 toArrayBuffer函数之后,我们就可以通过调用 app.js定义的 API来实现预览功能,具体的代码如下所示:
async function previewZipFile(path){ const fileName= fileNameEle.value;//获取文件名 const response= await request.get( `unzip/${fileName}/entry?path=${path}`); if(response.data&& response.data.status==="success"){ const{ entryData}= response.data; const entryBuffer= toArrayBuffer(entryData.data); const blob= new Blob([entryBuffer]);//使用URL.createObjectURL或blob.text()读取文件信息}}
由于完整的示例代码内容比较多,阿宝哥就不放具体的代码了。感兴趣的小伙伴,可以访问以下地址浏览示例代码。
由于完整的示例代码内容比较多,阿宝哥就不放具体的代码了。感兴趣的小伙伴,可以访问以下地址浏览示例代码。
注意:以上代码仅供参考,请根据实际业务进行调整。
在线解压 ZIP文件的两种方案,在实际项目中,建议使用服务器解压的方案。这样不仅可以解决浏览器的兼容性问题,而且也可以解决大文件在线解压的问题,同时也方便后期扩展支持其它的压缩格式。
二、JavaScript如何调试有哪些建议和技巧附五款有用的调试工具
我个人最喜欢Chrome开发者工具。虽然Safari和Firefox无法达到Chrome那么高的标准,但它们也在逐渐改善。在Firefox中,可以将Firebug和Firefox开发者工具组合使用。如果Firefox小组在改进内置开发者工具方面继续表现优异的话,Firebug有一天可能会被淘汰。
先把个人偏好放在一边,你应该能够在目标浏览器中对任意代码进行试验和调试。你的目标浏览器可能包括著名的IE8,也可能不包括。
要熟悉你自己选择的开发者工具。你还可以从IDE(集成开发环境)或者第三方软件获得额外的调试支持。
在各种调试工具中,调试的基础知识是相通的。事实上,我是在90年代从Borland的C开发者环境中学习的调试基础。断点、条件断点、监视与最新版Chrome开发者工具是完全相同的。2000年左右,我在Java中捕获到第一例异常。堆栈跟踪(Stack traces)的概念依然适用,即使JavaScript术语将其称作错误(Error),检查堆栈跟踪仍然和以前一样有用。
有些知识点是前端开发特有的。例如:
使用debugger语句可以在源代码中增加断点。一旦到达debugger语句,执行中断。当前作用域的上下文出现在控制台中,还有所有的局部变量和全局变量。将鼠标光标移到变量上可以查看变量的值。
还可以根据自己需要在开发者工具中插入断点和条件断点。在Chrome开发者工具中,在Sources视图中点击行号即可增加断点。如果在断点上点击右键并选择“编辑断点(Edit Breakpoint)”,你还可以增加断点条件。
如果你的任务是调试垃圾代码,你可能会有这样的问题:为什么DOM节点在执行过程中发生了改变。Chrome开发者工具提供了一种方便的断点,可用来检测元素树中的节点变化。
在Elements视图中,右键点击一个元素,从右键菜单中选择“Break on…”。
选定节点树状子目录(sub-tree)中的节点变化,
当记录对象或数组时,原始类型的值在引用对象记录中可能会发生变化。当查看引用类型时一定要记住,在记录和查看期间,代码执行可能会影响观测到的结果。
例如,在Chrome开发者工具中执行以下代码:
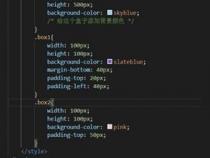
var wallets= [{ amount: 0}];setInterval( function(){ console.log( wallets, wallets[0], wallets[0].amount); wallets[0].amount+= 100;}, 1000);
记录的第二个和第三个属性的值是正确的,第一个属性中对象引用的值是不可靠的。当你第一次在开发者工具中显示这个属性时,amount域的值就已经确定了。无论你对同一个引用关闭并重新打开多少次,这个值都不会变化。
永远记得你在记录什么。记录原始类型时,使用带断点的watch表达式。如果是异步代码,避免记录引用类型。
在一些开发者工具中,你可以用console.table在控制台中记录对象数组。
尝试在你的Chrome开发者工具中执行下列代码:
console.table( [{ id: 1, name:'John', address:'Bay street 1'},{ id: 2, name:'Jack', address:'Valley road 2.'},{ id: 3, name:'Jim', address:'Hill street 3.'} ]);
输出是非常好看的表格。所有原始类型都立刻显示出来,它们的值反应记录时的状态。也可以记录复杂类型,显示内容为其类型,内容无法显示。因此,console.table只能用来显示具有原始类型值的对象构成的二维数据结构。
有时你可能会遇到错误的AJAX请求。如果你无法立刻确认提交请求的代码,XHR断点可以帮你节省时间。当提交某一特殊类型的AJAX时,XHR断点将会终止代码的执行,并将提交请求的代码段呈现给用户。
在Chrome开发者工具的Sources标签页中,其中一个断点类型就是XHR断点。点击+图标,你可以输入URL片段,当AJAX请求的URL中出现这个URL片段时,JavaScript代码将会中断。
Chrome开发者工具可以捕获所有类型的事件,当用户按下一个键、点击一下鼠标时,可以对触发的事件进行调试。
Chrome开发者工具可以在抛出异常时暂停执行JavaScript代码。这可以让你在Error对象被创建时观察应用的状态。
Sources标签页左侧面板上有一个代码片段(Snippet)子标签页,可用于保存代码片段,帮你调试代码。
如果你坚持使用控制台调试,反复写相同的代码,你应该将你的代码抽象成调试片段。这样的话,甚至还可以把你的调试技巧教给你的同事。
Paul Irish发布过一些基本的调试代码片段,例如在函数执行前插入断点。审查这些代码片段,并在网上搜索其他代码片段,这是很有价值的。
如果你可以得到函数调用的源代码,你还可以在函数调用前插入断点来终止函数的执行。如果你想调试f函数,用debug(f)语句可以增加这种断点。
(译者注:unminify解压缩并进行反混淆)
尽可能使用 source map。有时生产代码不能使用source map,但不管怎样,你都不应该直接对生产代码进行调试。
(译者注:sourcemap是针对压缩合并后的web代码进行调试的工具)
如果没有source map的话,你最后还可以求助于Chrome开发者工具Sources标签页中的格式化按钮(Pretty Print Button)。格式化按钮{}位于源代码文本区域的下方。格式化按钮对源代码进行美化,并改变行号,这使得调试代码更加方便,堆栈跟踪更加有效。
格式化按钮只有在不得已时才会使用。从某种意义上来说,丑代码就是难看,因为代码中的命名没有明确的语义。
Chrome开发者工具和Firebug都提供了书签功能,用于显示你在元素标签页(Chrome)或HTML标签页(Firebug)中最后点击的DOM元素。如果你依次选择了A元素、B元素和C元素,
如果你又选择了元素D,那么$0、$1、$2和$3分别代表D、C、B和A。
var f= function(){ g();} var g= function(){ h();}var h= function(){ console.trace('trace in h');}f();
Chrome开发者工具中的Sources标签页也在Watch表达式下面显示调用栈。
性能审查工具通常是很有用的。这些工具可以用于防止内存泄露,还可以检测到你的网站哪里需要优化。由于这些工具并不了解你的产品,你可以忽略其某些建议。通常来说,性能分析工具能够有效范围,可以使你的网站显著优化。
你可能熟悉某些调试技巧,其他技巧也会帮你节省不少时间。如果你开始在实践中使用这些技巧,我建议你几周之后重新阅读本文。你将会惊奇地发现,你的关注点在几周内就发生了变化。
JavaScript被称作以原型(prototype)为基础的语言。这种语言有很多特色,比如动态和弱类型,它还有一等函数(first class function)。另一个特点是它是一个多范型(multi-paradigm)语言,支持面向对象、声明式、函数式的编程风格。
JavaScript最初被用作客户端语言,浏览器实现它用来提供增强的用户接口。JavaScript在很多现代的网站和Web应用程序中都有应用。JavaScript的一个很棒的功能也很重要,就是我确实可以用它来提高或改善网站的用户体验。JavaScript也可以提供丰富的功能和交互的组件。
JavaScript在这技术高速发展的同时变得非常受欢迎。因为受欢迎JavaScript也改进了许多,修改JavaScript脚本有很多事要做。这次我们为开发者带来了几个非常有用的JavaScript调试工具。
可以调试任何WebKit程序,不仅仅是Safari浏览器。
源代码视图有语法高亮,可以设置断点。强大的搜索功能,支持正则表达式。
可以在任何网页编辑、调试和实时监视CSS、HTML和JavaScript。
Venkman是Mozilla的JavaScript调试器名称。它旨在为以Mozilla为基础的浏览器(Firefox, Netscape 7.x/9.x and SeaMonkey)提供一个强大的JavaScript调试环境。
三、如何通过javascript 使用 MQTT
在JavaScript中利用MQTT协议,首先你需要进行如下步骤:
1.下载并解压缩Apache ActiveMQ:访问官方网站()下载Apache ActiveMQ-5.9.0的二进制包,解压缩后进入bin文件夹。
2.启动服务:找到启动文件,通常是***.bat,双击运行。这将启动Apache ActiveMQ的服务。服务启动后,你会看到相应的提示信息,表示MQTT服务已经就绪。
3.客户端集成:对于Android客户端,你需要引入Paho MQTT客户端库,版本为1.0.**.jar。你可以在Paho MQTT的GitHub页面()上找到这个库,并将其添加到你的Android项目中。
4.连接和推送消息:在Android客户端中,使用Paho MQTT库的API来连接到ActiveMQ服务器,然后发送和接收消息。确保配置好服务器地址、端口号和主题等参数,以便客户端能够与MQTT服务进行有效的通信。
总的来说,通过JavaScript使用MQTT,你需要先启动MQTT服务,然后在客户端集成并配置相关库,最后进行连接和消息交互。这将为你提供一个可靠的实时通信平台。