Linux正则表达式与通配符
发布时间:2025-05-22 07:54:14 发布人:远客网络

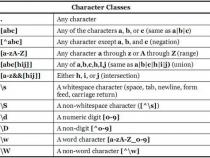
一、Linux正则表达式与通配符
正则表达式:在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。在很多文本编辑器或其他工具里,正则表达式通常被用来检索或替换那些符合某个模式的文本内容。正则表达式这个概念最初是由Unix中的工具软件(例如sed和grep)普及开的。
只有掌握了正则表达式,才能全面地掌握 Linux下的常用文本工具(例如:grep、egrep、GUN sed、 Awk等)的用法
grep-v代表反选,反向选择匹配到的内容
正则表达式分为三类(man grep可以看到,分别是basic RegExs,extended RegExs,perl RegExs)
1、基本的正则表达式(Basic Regular Expression又叫 Basic RegEx简称 BREs)
2、扩展的正则表达式(Extended Regular Expression又叫 Extended RegEx简称 EREs)
3、Perl的正则表达式(Perl Regular Expression又叫 Perl RegEx简称 PREs)
b.处理过程:查找文本文件中是否包含要查找的“关键字”(关键字可以是正则表达式),默认返回匹配的该行的内容
c. grep|egrep处理文件时,按行处理|
| sed| sed| sed-r|-| a.处理对象:文本文件
b.处理操作:对文本文件的内容进行查找、替换、删除、增加等操作
c. sed在处理文本文件的时候,按行处理|
| awk|-| awk|-| a. awk处理的对象:文本文件
b. awk处理操作:主要是对列进行操作|
注意:egrep或 sed-r默认使用扩展正则表达式(EREs),一般特殊字符({})可以不转义
grep-E以及egrep(Extend Regular Expression)
Linux通配符和三剑客的正则表达式是不一样的,因此,代表的意义也有较大的区别。
通配符一般用户命令行bash环境,而linux正则表达式用于grep, sed, awk场景。
示例:*的使用:代表任意0-N个字符,代表所有字符
二、C语言怎么用正则表达式
1、看到大家讨论这方面的东西,作点贡献聊表各位高手对这个版快的无私奉献:oops:
2、如果用户熟悉Linux下的sed、awk、grep或vi,那么对正则表达式这一概念肯定不会陌生。由于它可以极大地简化处理字符串时的复杂
3、度,因此现在已经在许多Linux实用工具中得到了应用。千万不要以为正则表达式只是Perl、Python、Bash等脚本语言的专利,作为C语言程序
4、员,用户同样可以在自己的程序中运用正则表达式。
5、标准的C和C++都不支持正则表达式,但有一些函数库可以辅助C/C++程序员完成这一功能,其中最著名的当数Philip Hazel的Perl-Compatible Regular Expression库,许多Linux发行版本都带有这个函数库。
6、为了提高效率,在将一个字符串与正则表达式进行比较之前,首先要用regcomp()函数对它进行编译,将其转化为regex_t结构:
7、int regcomp(regex_t*preg, const char*regex, int cflags);
8、参数regex是一个字符串,它代表将要被编译的正则表达式;参数preg指向一个声明为regex_t的数据结构,用来保存编译结果;参数cflags决定了正则表达式该如何被处理的细节。
9、如果函数regcomp()执行成功,并且编译结果被正确填充到preg中后,函数将返回0,任何其它的返回结果都代表有某种错误产生。
10、一旦用regcomp()函数成功地编译了正则表达式,接下来就可以调用regexec()函数完成模式匹配:
11、int regexec(const regex_t*preg, const char*string, size_t nmatch,regmatch_t pmatch[], int eflags);
12、参数preg指向编译后的正则表达式,参数string是将要进行匹配的字符串,而参数nmatch和pmatch则用于把匹配结果返回给调用程序,最后一个参数eflags决定了匹配的细节。
13、在调用函数regexec()进行模式匹配的过程中,可能在字符串string中会有多处与给定的正则表达式相匹配,参数pmatch就是用来保
14、存这些匹配位置的,而参数nmatch则告诉函数regexec()最多可以把多少个匹配结果填充到pmatch数组中。当regexec()函数成功返
15、回时,从string+pmatch[0].rm_so到string+pmatch[0].rm_eo是第一个匹配的字符串,而从
16、string+pmatch[1].rm_so到string+pmatch[1].rm_eo,则是第二个匹配的字符串,依此类推。
17、无论什么时候,当不再需要已经编译过的正则表达式时,都应该调用函数regfree()将其释放,以免产生内存泄漏。
18、函数regfree()不会返回任何结果,它仅接收一个指向regex_t数据类型的指针,这是之前调用regcomp()函数所得到的编译结果。
19、如果在程序中针对同一个regex_t结构调用了多次regcomp()函数,POSIX标准并没有规定是否每次都必须调用regfree()函
20、数进行释放,但建议每次调用regcomp()函数对正则表达式进行编译后都调用一次regfree()函数,以尽早释放占用的存储空间。
21、如果调用函数regcomp()或regexec()得到的是一个非0的返回值,则表明在对正则表达式的处理过程中出现了某种错误,此时可以通过调用函数regerror()得到详细的错误信息。
22、size_t regerror(int errcode, const regex_t*preg, char*errbuf, size_t errbuf_size);
23、参数errcode是来自函数regcomp()或regexec()的错误代码,而参数preg则是由函数regcomp()得到的编译结果,
24、其目的是把格式化消息所必须的上下文提供给regerror()函数。在执行函数regerror()时,将按照参数errbuf_size指明的最大字
25、节数,在errbuf缓冲区中填入格式化后的错误信息,同时返回错误信息的长度。
26、最后给出一个具体的实例,介绍如何在C语言程序中处理正则表达式。
27、static char* substr(const char*str, unsigned start, unsigned end)
28、 strncpy(stbuf, str+ start, n);
29、int main(int argc, char** argv)
30、 z= regcomp(®, pattern, cflags);
31、 regerror(z,®, ebuf, sizeof(ebuf));
32、 fprintf(stderr,"%s: pattern'%s'\n", ebuf, pattern);
33、 while(fgets(lbuf, sizeof(lbuf), stdin)){
34、 if((z= strlen(lbuf))>; 0&& lbuf[z-1]=='\n')
35、/*对每一行应用正则表达式进行匹配*/
36、 z= regexec(®, lbuf, nmatch, pm, 0);
37、 if(z== REG_NOMATCH) continue;
38、 regerror(z,®, ebuf, sizeof(ebuf));
39、 fprintf(stderr,"%s: regcom('%s')\n", ebuf, lbuf);
40、 for(x= 0; x< nmatch&& pm[x].rm_so!=-1;++ x){
41、 if(!x) printf("%04d:%s\n", lno, lbuf);
42、 printf("$%d='%s'\n", x, substr(lbuf, pm[x].rm_so, pm[x].rm_eo));
43、上述程序负责从命令行获取正则表达式,然后将其运用于从标准输入得到的每行数据,并打印出匹配结果。执行下面的命令可以编译并执行该程序:
44、#./regexp'regex[a-z]*'< regexp.c
45、0054: z= regexec(®, lbuf, nmatch, pm, 0);
46、对那些需要进行复杂数据处理的程序来说,正则表达式无疑是一个非常有用的工具。本文重点在于阐述如何在C语言中利用正则表达式来简化字符串处理,以便在数据处理方面能够获得与Perl语言类似的灵活性。
三、正则表达式
1、“.表示任意字符,这里用\把它转义成点这个字符
2、\本身就是代表转义,再给它的转义不就成了\这个符号了吗?”
3、可以看出,你认为"."前面的"\"有对"."进行转义。事实上并不是这样的,前一个\对后一个\进行了转义,得到了\本身,之后没有拿转义后的\接着去转义.。
4、"\\.class",只是要去匹配一个文本的"\"和一个“任意字符”和文本"class"。具体情况可使用grep进行验证。
5、me@ubuntu:grep$grep-E'.*[Zz].*\\.class'jdx.txt
6、123zZz\{classe
当然这里我假设你要匹配的是文本字符,我使用的是grep进行的验证,环境是bash,可能与你的发生问题的环境不同。
7、当然这里我假设你要匹配的是文本字符,我使用的是grep进行的验证,环境是bash,可能与你的发生问题的环境不同。