Postgresql 中的 正则表达式 模式匹配
发布时间:2025-05-21 21:03:13 发布人:远客网络
一、Postgresql 中的 正则表达式 模式匹配
1、PostgreSQL中正则表达式是用于模式匹配的强大工具,它提供了灵活且强大的文本搜索和替换能力。本文将深入探讨PostgreSQL中正则表达式的使用方法和特性。
2、在PostgreSQL中,正则表达式操作符包括~~、~~*、!~~和!~~*,它们分别对应LIKE的LIKE、ILIKE、NOT LIKE和NOT ILIKE操作。这些操作符允许进行模式匹配,如字符串匹配或大小写不敏感的匹配。
3、~~和~~*等同于LIKE和ILIKE操作,其中~~使用标准SQL正则表达式理解模式,而~~*则允许大小写不敏感的匹配。所有这些操作符都是PostgreSQL的扩展,不属于标准SQL。
4、为了在模式中匹配特定字符如下划线(_)或百分号(%),需要在模式字符串中前导一个反斜线(\)作为逃逸字符。例如,要匹配文本中的下划线或百分号,模式应为\_%或\_\_。通过使用ESCAPE子句,可以指定一个不同的逃逸字符,这样正斜线就不会被理解为特殊字符。
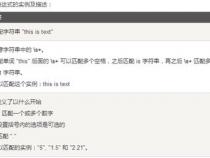
5、在使用正则表达式时,可以使用LIKE操作符的灵活特性,如通配符(_匹配任何单个字符,%匹配任意长度的字符序列)来匹配字符串内的任何位置。但要匹配整个字符串,模式需要以百分号开头和结尾。同时,LIKE操作符的匹配是大小写敏感的。
6、如需大小写不敏感的匹配,可以使用ILIKE操作符代替LIKE。此外,SIMILAR TO操作符提供了与标准SQL正则表达式兼容的匹配方法,允许使用_和%作为通配符,类似于POSIX正则表达式中的.和.*。
7、SIMILAR TO操作符支持额外的模式匹配元字符,如选择符(|)、重复符(*、+、?、{m}、{m,n}等),以及方括号表达式和圆括号(用于逻辑组合和子表达式)。这些元字符允许更复杂的模式匹配。
8、为了从匹配到的正则表达式中提取特定子串,可以使用substring函数。在SIMILAR TO中,需要在模式中包含两次逃逸字符和双引号以明确指定返回的子串。
9、正则表达式的匹配操作符和函数(如regexp_replace、regexp_match、regexp_matches、regexp_split_to_table和regexp_split_to_array)提供了对匹配到的子串进行替换、获取、分割等操作的能力。这些函数允许使用圆括号来捕获子表达式,并使用特殊符号来引用或替换它们。
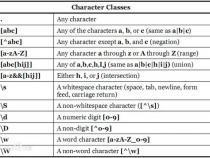
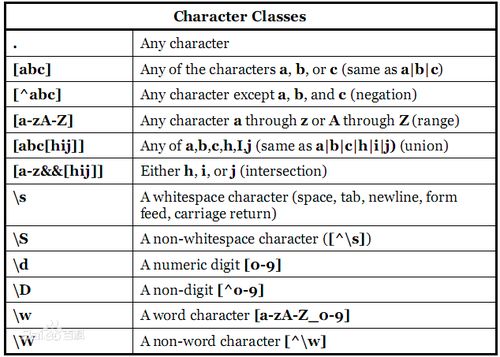
10、在正则表达式中使用方括号表达式时,可以定义一个字符类,用于匹配或排除特定字符。例如,[^字符列表]匹配不在列表中的字符,而[\s\S]则匹配任何字符([\s\S]*表示懒惰匹配,而[\s\S]*不带?号表示贪婪匹配)。
11、最后,需要注意正则表达式的一些细节,如量词的使用规则(不能紧跟在另一个量词后面,不能作为表达式或子表达式的开头,不能跟在^或|后面)以及方括号表达式的特殊用法(如在列表中包含特定字符或表示字符范围)。
12、通过掌握这些特性,开发者和数据库用户可以充分利用PostgreSQL的正则表达式功能,进行更高效和精确的文本处理和搜索操作。
二、postgresql如何查询字符串中是否包含某字符
1、PostgreSQL中查询字符串包含特定字符,可使用LIKE或SIMILAR TO运算符。
2、例如查询字符串字段field中包含字符"a"的SQL语句如下:
3、使用LIKE运算符:`SELECT* FROM table WHERE field LIKE'%a%'`
4、使用SIMILAR TO运算符:`SELECT* FROM table WHERE field SIMILAR TO'%a%'`
5、LIKE为模糊匹配,SIMILAR TO则基于正则表达式。后者提供更精确的匹配。
6、另一种方法是利用POSITION函数,返回字符"a"在字段field中的位置,不存在则返回0。通过检查POSITION的返回值是否大于0,即可判断字段field是否包含字符"a"。
三、mysql和postgresql的区别
二、任何系统都有它的性能极限,在高并发读写,负载逼近极限下,PG的性能指标仍可以维持双曲线甚至对数曲线,到顶峰之后不再下降,而 MySQL明显出现一个波峰后下滑(5.5版本之后,在企业级版本中有个插件可以改善很多,不过需要付费)。
三、PG多年来在 GIS领域处于优势地位,因为它有丰富的几何类型,实际上不止几何类型,PG有大量字典、数组、bitmap等数据类型,相比之下mysql就差很多,instagram就是因为PG的空间数据库扩展POSTGIS远远强于MYSQL的my spatial而采用PGSQL的。
四、PG的“无锁定”特性非常突出,甚至包括 vacuum这样的整理数据空间的操作,这个和PGSQL的MVCC实现有关系。
五、PG的可以使用函数和条件索引,这使得PG数据库的调优非常灵活,mysql就没有这个功能,条件索引在web应用中很重要。
六、PG有极其强悍的 SQL编程能力(9.x图灵完备,支持递归!),有非常丰富的统计函数和统计语法支持,比如分析函数(ORACLE的叫法,PG里叫window函数),还可以用多种语言来写存储过程,对于R的支持也很好。这一点上MYSQL就差的很远,很多分析功能都不支持,腾讯内部数据存储主要是MYSQL,但是数据分析主要是HADOOP+PGSQL(听李元佳说过,但是没有验证过)。
七、PG的有多种集群架构可以选择,plproxy可以支持语句级的镜像或分片,slony可以进行字段级的同步设置,standby可以构建WAL文件级或流式的读写分离集群,同步频率和集群策略调整方便,操作非常简单。
八、一般关系型数据库的字符串有限定长度8k左右,无限长 TEXT类型的功能受限,只能作为外部大数据访问。而 PG的 TEXT类型可以直接访问,SQL语法内置正则表达式,可以索引,还可以全文检索,或使用xml xpath。用PG的话,文档数据库都可以省了。
九,对于WEB应用来说,复制的特性很重要,mysql到现在也是异步复制,pgsql可以做到同步,异步,半同步复制。还有mysql的同步是基于binlog复制,类似oracle golden gate,是基于stream的复制,做到同步很困难,这种方式更加适合异地复制,pgsql的复制基于wal,可以做到同步复制。同时,pgsql还提供stream复制。
十,pgsql对于numa架构的支持比mysql强一些,比MYSQL对于读的性能更好一些,pgsql提交可以完全异步,而mysql的内存表不够实用(因为表锁的原因)
最后说一下我感觉 PG不如 MySQL的地方。
第一,MySQL有一些实用的运维支持,如 slow-query.log,这个pg肯定可以定制出来,但是如果可以配置使用就更好了。
第二是mysql的innodb引擎,可以充分优化利用系统所有内存,超大内存下PG对内存使用的不那么充分,
第三点,MySQL的复制可以用多级从库,但是在9.2之前,PGSQL不能用从库带从库。
第四点,从测试结果上看,mysql 5.5的性能提升很大,单机性能强于pgsql,5.6应该会强更多.
第五点,对于web应用来说,mysql 5.6的内置MC API功能很好用,PGSQL差一些。
pgsql和mysql都是背后有商业公司,而且都不是一个公司。大部分开发者,都是拿工资的。
说mysql的执行速度比pgsql快很多是不对的,速度接近,而且很多时候取决于你的配置。
对于存储过程,函数,视图之类的功能,现在两个数据库都可以支持了。
另外多线程架构和多进程架构之间没有绝对的好坏,oracle在unix上是多进程架构,在windows上是多线程架构。
很多pg应用也是24/7的应用,比如skype.最近几个版本VACUUM基本不影响PGSQL运行,8.0之后的PGSQL不需要cygwin就可以在windows上运行。
至于说对于事务的支持,mysql和pgsql都没有问题。