大数据ClickHouse进阶(二十六):ClickHouse数据备份
发布时间:2025-05-21 14:28:04 发布人:远客网络
一、大数据ClickHouse进阶(二十六):ClickHouse数据备份
1、在ClickHouse中,利用副本确保数据高可用性,但副本不支持防止数据误删等操作。为了应对这类风险,ClickHouse提供了多种备份方法。以下将详细介绍几种备份方法的使用。
2、首先,对于数据体量较小的场景,可采用导出文件备份。具体操作通过执行`dump`命令,将数据导出为本地文件。数据备份后,可通过反向执行`dump`命令将数据还原到表中。
3、其次,可利用快照表进行备份。此方法需先创建与原表结构一致的表,然后使用`Insert into select`语句将原表数据复制到备份表中。若需考虑容灾,可将备份表放置于不同节点,备份SQL命令中需包含远程集群相关参数。
4、针对基于数据分区的备份,ClickHouse提供了两种方式:FREEZE与FETCH。使用FREEZE备份时,通过执行特定语法,将分区数据保存至指定目录,记录备份次数的文件会同步生成。备份后,通过ATTACH命令将分区文件恢复至表中。同样的,FETCH备份支持ReplicatedMergeTree表引擎,原理与ReplicatedMergeTree同步数据类似。备份分区后,数据将存储于本地指定目录,同样需要通过ATTACH命令实现分区恢复。
5、值得注意的是,无论使用FREEZE还是FETCH备份,都无法备份表的元数据。为了确保备份完整性,还需将元数据单独备份。元数据位于`/var/lib/ClickHouse/metadata/{database}`目录下,找到对应表的SQL文件保存。
6、综上所述,ClickHouse提供了多样化的数据备份策略,包括导出文件备份、快照表备份、基于分区的FREEZE与FETCH备份等,这些方法均能有效防止数据误删,并确保数据高可用性。通过合理选择并实施备份策略,用户可大幅提升数据安全与恢复能力。
二、阿里云数据库 ClickHouse 产品和技术解读
1、摘要:本文深入解析阿里云数据库ClickHouse产品能力与特性,包括同步MySQL库、ODPS库、本地盘及多盘性价比实例,以及自建集群上云的迁移工具。同时,介绍阿里云在云原生ClickHouse的最新进展。
2、在2023云数据库技术沙龙“MySQL x ClickHouse”专场上,阿里云数据库ClickHouse技术研发刘扬宽,分享了《阿里云数据库ClickHouse产品与技术》的核心内容。
3、刘扬宽,阿里云内部的“留白”花名持有者,拥有10余年数据存储与数据处理系统研发经验,曾在中科院计算所、中国移动苏州研发中心参与过存储系统研发工作。自2019年加入阿里云,负责内部产品的存储计算分离架构升级,在云原生ClickHouse的研发中,主要负责存储模块,针对计算层特点优化存储系统,显著提升了云原生ClickHouse的性能。
4、ClickHouse产品自2019年中旬开源,迅速在社区中获得认可,排名上升迅猛,在DB-Engine趋势图中表现亮眼。开源初期虽晚,但其热度排名遥遥领先于其他分布式数据库。
5、社区版ClickHouse采用Sharding架构,集群实例需要创建分布式表,并定义Sharding key,数据将分布至不同计算节点,通过节点副本、复制同步机制确保高可用性。
6、分布式查询链路中,用户查询数据时,需使用分布式表,并将查询分发至查询节点。节点解析后,找到对应本地表,确定集群分布式表的下载节点,将查询发送至这些节点。节点进行本地计算,将中间结果返回给Push节点,最终汇总返回给用户。
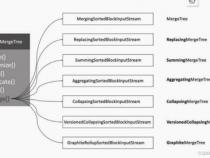
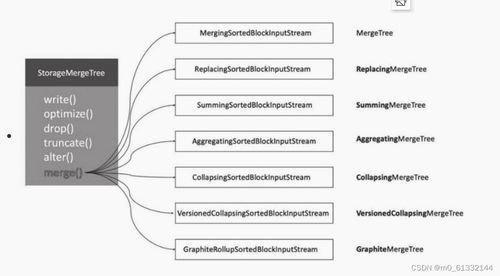
7、ClickHouse提供多种表引擎,如Meterialized MySQL使用ReplacingMergeTree进行去重,MergeTree系列为核心表引擎,支持后台合并数据并聚合运算,提高查询效率。
8、社区生态中,创建外部表引擎有利于数据从其他系统同步至ClickHouse。SQL示例展示如何创建本地表和分布式表,本地表需包含排序键,未指定分区键时,默认为整个表作为分区。用户可指定数据生命周期,告知系统哪些数据移动至冷存储或删除。
9、ClickHouse的高可用性主要通过设置副本数量实现,内部数据同步通过JK协调,支持多点写入与查询。副本数量适应不同Sharding策略需求。
10、ClickHouse专为OLAP设计,底层基于MergeTree逻辑二维表存储,每个行对应数据目录下的PART。数据块格式支持高效读取、轻索引及压缩,但点查询性能一般。
11、性能方面,ClickHouse具有高性能读取、高吞吐量与压缩比高。LSM树结构优化写入效率,P2P架构支持多种Sharding策略。后台异步执行Delete和Update操作,提升效率。
12、ClickHouse采用纯列存储,支持多种压缩算法,实现数据高效存储与查询。高可用性通过设置任意数量的副本实现,内部复制机制支持多点写入与查询。
13、在分析场景下,ClickHouse性能高,得益于硬件优化、多线程模型、向量化执行、内存友好的设计与代码重构。支持近似算法、抽样方法、丰富数据类型及窗口函数,具有查询队列与资源隔离特性。
14、ClickHouse具备预先建模能力,通过创建物化视图进行聚合计算,提升查询速度。数据格式设计细致,适用于不同场景与数据大小。
15、在不同场景下,ClickHouse提供聚合算子,针对数据类型与大小自适应使用函数处理。内存使用上,使用不同内存分配函数,优化性能。
16、处理大量数据时,ClickHouse执行UV操作表现出色。性能对比显示,相较于其他分析型数据库,ClickHouse在单表过滤、分组、聚合查询上优势显著。
17、社区版ClickHouse存在限制,如写入限制、数据一致性保证、事务支持等。计算层次的限制影响join性能,优化器对CPU优化的考虑有限。用户接口复杂,创建表需同时建立本地表与分布式表,增加学习成本。
18、运维方面,ClickHouse需要手动操作,数据不会自动重平衡,副本失败时需手动重建或恢复。缺乏实时数据迁移工具与备份恢复功能。配置管理不易,部分设置不可持久化。
19、阿里云数据库ClickHouse主打性能、成本与灵活性,为海量数据分析提供最佳解决方案。主打场景包括大宽表查询、数据hash对齐join等,提供批量更新和删除操作优化。
20、阿里云数据库ClickHouse与开源版在运维、数据生态与内核研发上有所不同。运维方面提供可视化集群管理,自动处理异常与数据迁移。容灾备份功能齐全,支持日志审计、白名单、RAM授权等安全措施。
21、水平扩缩容节点自动迁移,数据无需锁写,切换SLB时短暂切换。用户权限管理通过RAM子账号实现,支持从阿里云内部系统同步数据至ClickHouse。
22、内核优化方面,支持分层存储与可分离MPP架构功能,提供用户友好的设计和优化建议。数据冷热分层提供成本优化方案,用户可根据数据生命周期调整存储。
23、阿里云ClickHouse支持冷热分层存储策略,数据移动至成本更低的存储层,如云盘、OSS或HDD,降低整体成本。本地盘用作小文件缓存,优化查询性能。
24、多盘存储方案提供性价比,通过RAID零或LVM构建存储结构,支持多盘聚合带宽。分层存储组合根据业务场景选择,实现冷温热数据的灵活管理。
25、为方便用户迁移自建ClickHouse集群至云端,阿里云提供迁移工具cksync,解决数据实时同步问题。配合Pass Log功能,实现数据整合与一致性。
26、云原生ClickHouse技术演进中,存储计算分离架构与多计算组实现资源高效管理,解决节点计算资源扩缩容与多租户资源隔离问题。
三、ClickHouse介绍
1、ClickHouse,一款由俄罗斯Yandex公司于2016年开源的用于在线分析处理查询(OLAP)的MPP架构列式存储数据库(DBMS)。它的全名是Click Stream,Data WareHouse,具有强大的用户行为分析能力和流批一体特性。ClickHouse以本地附加存储作为存储方式,拥有线性扩展和可靠性保障,支持分片+复制。
2、列式存储在数据库设计中具有明显优势。相较于行式存储,列式存储能够更高效地处理大量数据中的特定查询,例如查询所有人的年龄,它避免了不必要的数据遍历,提高了查询效率。
3、ClickHouse提供几乎覆盖标准SQL的大部分语法,包括DDL和DML,以及配套的函数和用户管理权限等,支持数据的备份与恢复,具备强大的DBMS功能。
4、它提供多样化的引擎类型,包括合并树、日志、接口和其他类引擎,总数达20多种。此外,ClickHouse采用类LSM Tree结构,提供高吞吐量的写入能力,利用顺序写入优化磁盘性能,通过后台的合并操作,实现数据的高效管理和维护。
5、ClickHouse通过数据分区和多线程处理实现极致的并行处理能力,每个partition由多个索引粒度和CPU核心共同处理,单条查询能够充分利用所有CPU资源,有效降低查询延时。
6、ClickHouse在单表查询速度上优于关联查询,关联查询时会将右表加载到内存,进一步提升查询效率。同时,它利用C++的硬件优势,摒弃Hadoop生态,数据底层以列式存储,支持向量化处理和预先设计运算模型,为数据建立多级索引,使用大量算法优化数据处理流程。
7、引擎在ClickHouse中扮演着核心角色,决定了数据的存储位置、结构、表的特征以及是否支持并发操作等关键特性。支持的数据库引擎有5种,而表引擎则决定了数据的存储方式和表的特征。
8、若想深入了解ClickHouse,推荐阅读相关书籍,以获取更详尽的技术知识和实践经验。