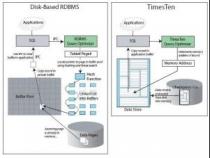
secbase数据库使用方法
发布时间:2025-05-21 11:37:40 发布人:远客网络
一、secbase数据库使用方法
sybase安装完成后,在程序----sybase中有这样几项:
Sybase Software Asset Management(SySAM)
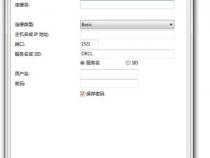
欲进行数据库相关操作,首先需建立服务器.即在server config下完成相
关配置工作.点击开始----程序-----sybase----server config在左面方框中选中
adaptive server,在右面方框中点击create adaptive server来创建一个adaptive
服务器.按提示输入服务器名和路径等相关设置.当进行到有error log画面时有,
先选择Network Address,进入后点击add,在connection中输入ip与端口号5000,如:
192.168.0.107,5000点击OK退出后再点configure default xp server按上面的方
法同样进行配置不过注意此时端口号为5004,配置完成后点ok退出后再点continue等
待服务器配置一段时间后即可完成服务器的新建工作.
点击开始----程序----sybase-----sybase centre那一长项,即可进入Sybase
Centre界面,点工具,连接先建立的服务器之后,就可以在其中可以直接进行数据库
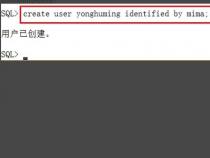
点击开始----程序----sybase-----sql advantage点server连接上建立好的
服务器后,也可以在其中直接输入SQL脚本直接进行对数据库服务器的一些相关操作.
1,建立两个设备testdata,testlog大小分别为500M,400M.并写出SQL脚本.
点服务器名,点Database Devices在右面的窗格中点add Database
Devices按提示即可完成新建工作.
physname="g:/sybase/testdata.dat",
vdevno= 2,size="500M"
phyname="g:/sybase/testlog.dat",
vdevno= 3,size="400M"
2,将上面建的设备中的testlog扩展为500M,并写出SQL脚本.
选中Database Devices中的 testlog点击右键,选择属性.在常规选项卡
size="100M"//注这里填的是增加的大小.
点到Databases在其右边的窗格中点add项按提示完成.
log on testlog="200M"
点到test右键属性,点到Devices选项卡,先择edit即可.
alter database test on testdata="100M"
alter database test log on testlog="50M"
create table test(testno varchar(8),testcontern varchar(20))
insert test values('01','tanmiy')
先启动backup server,然后点到要备份的数据库,右键先backup按提
dump database test to"g:/sybase/backup/testdump.dump"
新建一个数据库与欲恢复的数据库同名且存储
状态相同,右键选择restore,完成后使用online database数据库名激
load database test from"g:/sybase/backup/testdump.dump"
二、mysql数据库schema是什么
1、schema在数据库中表示的是数据库对象集合,它包含了各种对像,比如:表,视图,存储过程,索引等等。
2、一般情况下一个用户对应一个集合,为了区分不同的集合就需要给不同的集合起名字。用户的schema名就相当于用户名,并作为该用户缺省schema。
3、所以说,schema集合看上去像用户名。例如,当访问一个数据表时,如果该表没有指明属于哪个schema,系统就会自动的加上缺省的schema。
4、Schema的创建在不同的数据库中要创建的Schema方法是不一样的,但是它们有一个共同的特点就是都支持CREATE SCHEMA语句。
5、在MySQL数据库中,可以通过CREATE SCHEMA语句来创建一个数据库Oracle Database在Oracle中,由于数据库用户已经创建了一个模式,所以,CREATE SCHEMA语句创建的是一个schema,它允许将schema同表和视图关联起来,并在这些多个事务中发出多个SQL语句。
6、SQL Server在SQL Server中,CREATE SCHEMA会按照名称来创建一个模式,与MySQL不同,CREATE SCHEMA语句创建了一个单独定义到数据库的模式。和Oracle数据库也有不同,它实际上创建了一个模式,而且一旦创建了模式,就可以往模式中添加用户和对象。
三、优化MYSQL数据库的方法
在开始演示之前,我们先介绍下两个概念。
概念一,数据的可选择性基数,也就是常说的cardinality值。
查询优化器在生成各种执行计划之前,得先从统计信息中取得相关数据,这样才能估算每步操作所涉及到的记录数,而这个相关数据就是cardinality。简单来说,就是每个值在每个字段中的唯一值分布状态。
比如表t1有100行记录,其中一列为f1。f1中唯一值的个数可以是100个,也可以是1个,当然也可以是1到100之间的任何一个数字。这里唯一值越的多少,就是这个列的可选择基数。
那看到这里我们就明白了,为什么要在基数高的字段上建立索引,而基数低的的字段建立索引反而没有全表扫描来的快。当然这个只是一方面,至于更深入的探讨就不在我这篇探讨的范围了。
这里我来说下HINT是什么,在什么时候用。
HINT简单来说就是在某些特定的场景下人工协助MySQL优化器的工作,使她生成最优的执行计划。一般来说,优化器的执行计划都是最优化的,不过在某些特定场景下,执行计划可能不是最优化。
比如:表t1经过大量的频繁更新操作,(UPDATE,DELETE,INSERT),cardinality已经很不准确了,这时候刚好执行了一条SQL,那么有可能这条SQL的执行计划就不是最优的。为什么说有可能呢?
如果f1的值刚好频繁更新的值为30,并且没有达到MySQL自动更新cardinality值的临界值或者说用户设置了手动更新又或者用户减少了sample page等等,那么对这两条语句来说,可能不准确的就是B了。
这里顺带说下,MySQL提供了自动更新和手动更新表cardinality值的方法,因篇幅有限,需要的可以查阅手册。
那回到正题上,MySQL 8.0带来了几个HINT,我今天就举个index_merge的例子。
表t1实际上在rank1,rank2,rank3三列上分别有一个二级索引。
显然,没有用到任何索引,扫描的行数为32034,cost为3243.65。
我们加上hint给相同的查询,再次看看查询计划。
这个时候用到了index_merge,union了三个列。扫描的行数为1103,cost为441.09,明显比之前的快了好几倍。
对比下以上两个,加了HINT的比不加HINT的cost小了100倍。
总结下,就是说表的cardinality值影响这张的查询计划,如果这个值没有正常更新的话,就需要手工加HINT了。相信MySQL未来的版本会带来更多的HINT。