java里.matches方法有什么用
发布时间:2025-05-20 17:03:27 发布人:远客网络

一、java里.matches方法有什么用
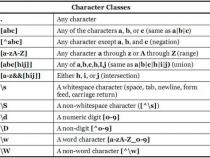
1、match()的参数一般为正则表达式,现在两个正则表达式,可以试用
2、正则表达式一:可以适用任何形式的字符串,
3、其中LikeType是要匹配的字符串,patten是生成的正则表达式,sourceStr是已有字符串,判断sourceStr是否满足LikeType的正则表达式
4、public static void main(String[] args){
5、// TODO Auto-generated method stub
6、String pattern="[a-zA-Z0-9]*["+ likeType+"]{1}[a-zA-Z0-9]*";
7、String sourceStr="adfjaslfj23ldfalsf";
8、System.out.println(sourceStr.matches(likeType));
9、正则表达式二:固定位置的字符串匹配,理解同上,只是正则表达式的不同
10、public static void main(String[] args){
11、// TODO Auto-generated method stub
12、likeType= likeType.replaceAll("%","\\\\d").replaceAll("\\*","\\\\d\\*");
13、System.out.println(sourceStr.matches(likeType));
14、match的方法比较简单,但绝对实用,所以要掌握用法,正则表达式的写法尤其重要。
二、java应用程序集成hanLP实现自然语言分词+match(mysql)
自然语言处理(NLP)是一门将计算机科学与语言学相结合的交叉学科,旨在利用计算模型解析、理解及生成人类语言。NLP涉及词性标注、命名实体识别、句法分析等多个任务,旨在实现语言的自动化处理。
自然语言分词是NLP的基础,旨在将连续的文本分割成独立的词语或词素。例如,句子“你好美丽的祖国大地,你好美丽的大好河山”在分词后变为“你好美丽的祖国大地,你好美丽的大好河山”,这有助于计算机理解其结构。
实现自然语言分词的框架众多,如SnowNLP、Thulac、HanLP、LTP和CoreNLP等。HanLP是一个面向生产环境的多语言自然语言处理工具包,基于PyTorch和TensorFlow 2.x双引擎,提供全面的NLP功能,包括词干提取、分词、词性标注、命名实体识别等。
Java应用程序集成HanLP实现自然语言分词通常涉及以下几个步骤。首先,下载汉LP的语言包,并将其解压并放置在指定目录。随后,在资源文件夹中创建hanlp.properties配置文件,指定语言包根目录。接着,编写Java代码,包括Word类、Tokenizer类和TokenizerTester类,用于处理文本分词。
在代码中,首先引入POM依赖,然后编写分词代码,输入字符串“你好美丽的祖国大地,你好美丽的大好河山”,输出结果应按照中文分词规则进行正确分割。
值得一提的是,HanLP在数据处理与拆分比例、命名实体识别、语法标准及语料库等方面提供了改进与优化,致力于推动中文NLP的透明化与个性化训练。通过集成HanLP,数据库可以增加FULLTEXT类型索引,解决中文全文索引不适用的问题,以提高检索效率。
综上所述,通过Java应用程序集成HanLP实现自然语言分词,可以有效提高文本处理的准确性和效率,满足不同应用场景的需求,同时支持个性化词库训练,增强系统适应性和灵活性。
三、es(4)—查询条件match和term
1、而文档在倒排索引中存储的是什么值呢?可以通过下面uri进行分析:
2、有上图可知,倒排索引存储的值实际上是 es和 book,而不是 es book。
3、注意:因为是默认被standard analyzer分词器分词,大写字母全部转为了小写字母,并存入了倒排索引以供搜索。term是确切查询,所以传入的条件要和倒排索引保持一致。
4、需要注意的是,倒排索引中存储的值为大写的 ES BOOK。
5、使用term查询时,查询条件不会进行分词。但是 text类型的数据,在倒排索引中实际存储的是分词的数据。
6、 term条件的区分大小写,而实际上,text数据经过默认的standard analyzer分词器分词,大写字母全部转为了小写字母,并存入了倒排索引以供搜索。
7、故不推荐使用term去查询text类型。
8、 term去查询keyword的数据,均不会进行分词,但是需要注意大小写
9、 match查询text类型时,其本质的操作为or。
10、并且match匹配时,底层分词器会将条件转换为小写,故和text的倒排索引的大小写保持一致。即不区分大小写。
11、上文说到,match默认使用or的操作。那么如何替换为and操作?
12、查询到的数据即包含JAVA也要包含BOOK。
13、再次执行时,依旧可以查询到 JAVA AND NET BOOK数据。
14、 and操作,是要求倒排索引中即要包含 java也需要包含 book。
15、 match查询keyword操作时,等效term
16、当match查询text类型时,在底层将会被转换为term操作。