究竟是什么让Redshift比Hive快10倍
发布时间:2025-05-20 11:25:00 发布人:远客网络
一、究竟是什么让Redshift比Hive快10倍
1、究竟是什么原因产生了如此悬殊的速度,有网友在Quora上提出了这个问题,并得到了Reynold Xin的解答:
2、Redshift采用了专有的叫做ParAccel的并行数据库实现机制。我想在很多工作情境中,你会发现大多数并行数据库引擎要比Hive快。接下来,我将给出答案,并解释其中的某些原因。请注意的是,虽然该答案针对的是ParAccel,其中的大部分因素也适用于Vertica、Greenplum、OracleRAC等并行数据库。
3、在答案中呢,我将使用三个可互换的术语“并行数据库”、“关系型数据库”和“分析型数据库”。
4、比起并行数据库,Hive在可扩展性、灵活度方面遥遥领先。例如,Facebook使用Hive数据仓库跨越成千上万个节点。说起灵活度,Hive设计的初衷是与一些系列存储系统(HDFS、HBase、S3)配合使用,并能够支持多种输入格式(压缩、未压缩、Avro、纯文本、JSON)。
5、易扩展和高灵活度在给你带来便利的同时,却也阻碍了你构建性能更好的查询引擎。接下来,我将列举哪些特征会影响查询性能:
6、数据格式:数据以类似纯文本文件,相对未优化的形式存储在HDFS中。Hive作业在处理数据之前,需要先花大量时间从硬盘中读取数据,再反序列化这些数据。
7、发起任务的系统开销:Hadoop MapReduce使用心跳机制(heartbeats)制定作业计划,每项任务作为一独立的JVM过程发起。在Hadoop MapReduce中,仅仅是发起一项作业就需要几十秒钟,在秒级时间单位内,是无法运行任何进程的。相反,并行数据库拥有持续进程或线程池,它们能够大大减少任务安排及发起所需要的系统开销。
8、中间数据物化 vs数据传输:Hive使用拥有二阶模型(Map和Reduce)的MapReduce来执行。通常一个复杂的SQL查询被映射为MapReduce的多个阶段,不同阶段的中间数据在硬盘上物化。并行数据库内置有用于执行SQL查询的引擎,执行查询时,该引擎在查询操作符和数据流(steram data)之间跨节点传递数据。
9、列数据格式:列数据库将数据按照列式的格式进行存储。在典型的数据仓库中,每张数据表能够存储成百上千列,而大多数查询仅查找少数列。让我们来考虑一下如下查询,要查找的是沃尔玛每家店的营业额。它仅需要查找两三列(商店的编号、每件商品的零售价,或者还有销售日期)。以列式存储数据,执行查询时,引擎可以跳过不相关的列。这样可以减少上百次的硬盘I/O。此外,按列存储数据能够大大增加压缩比率。
10、列查询引擎:除了上面提到的按列式存储的数据格式,还可以按列构建查询执行引擎,该引擎在分析型工作负载方面得到了较好的优化。其中的技巧包括:晚期物化(late materialization)、直接操作压缩过的数据、利用现代CPU提供的向量化操作(SIMD)。
11、更快的S3连接:在这里我将给出一个大胆的猜测:AWS可能已经为他们的Redshift实例实现了一个比普通S3能够提供的更高带宽的S3整体负载。
12、我需要申明,我们刚刚讨论的这些因素是基于Hive当前版本(2013年2月)。毫无置疑,Hive社区将会推进开发工作,并解决其中的一些难题。
二、Navicat Premium 同时可以连接多少个数据库
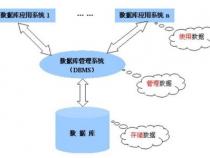
1、Navicat Premium是一套数据库开发工具,它支持同时连接 MySQL、MariaDB、MongoDB、SQL Server、Oracle、PostgreSQL和 SQLite七大主流数据库。它与 Amazon RDS、Amazon Aurora、Amazon Redshift、Microsoft Azure、Oracle Cloud、MongoDB Atlas、阿里云、腾讯云和华为云等云数据库兼容。你可以快速轻松地创建、管理和维护数据库。
2、另外,Navicat也有支持单一数据库连接的版本:
3、Navicat for MySQL(关系型数据库):它是管理和开发 MySQL或 MariaDB的理想解决方案。它是一套单一的应用程序,能同时连接 MySQL和 MariaDB数据库,并与 Amazon RDS、Amazon Aurora、Oracle Cloud、Microsoft Azure、阿里云、腾讯云和华为云等云数据库兼容。这套全面的前端工具为数据库管理、开发和维护提供了一款直观而强大的图形界面。
4、Navicat for PostgreSQL(关系型数据库):它是一套易于使用的图形化 PostgreSQL数据库开发工具。从编写简单的 SQL查询到开发复杂的数据库,它能满足大部分用户的需要,包括 PostgreSQL初学者以及经验丰富的开发人员。它能连接任何本地或远程 PostgreSQL服务器,并支持 Amazon Redshift、Amazon Aurora、Amazon RDS、Microsoft Azure、阿里云、腾讯云、华为云等云数据库和所有 PostgreSQL数据库对象。
5、Navicat for MongoDB(非关系型数据库):它的高效图形用户界面,用于管理和开发 MongoDB数据库。它能连接本地或远程的 MongoDB服务器,以及与 MongoDB Atlas、阿里云、腾讯云和华为云兼容。为管理、监控、查询和可视化数据提供了卓越的功能,轻松提高日常 MongoDB操作的效率。
6、Navicat for MariaDB(关系型数据库):它为 MariaDB数据库管理和开发提供了一个原生环境,能连接本地或远程的 MariaDB服务器,并与 Amazon RDS和腾讯云兼容。它支持大部分附加的功能,例如新的存储引擎、微秒、虚拟列等。
7、Navicat for SQL Server(关系型数据库):它为 SQL Server数据库管理和开发提供了全方位的图形化的解决方案。能快速轻松地创建、编辑和删除所有数据库对象,或运行 SQL查询和脚本。连接任何本地或远程 SQL Server,并与云数据库(如 Amazon RDS、Microsoft Azure、阿里云、腾讯云和华为云)兼容。
8、Navicat for Oracle(关系型数据库):它能透过精简的工作环境,提高 Oracle开发人员和管理员的效率和生产力。最佳化 Oracle的开发-快速安全地创建、组织、访问和共享信息。它与云数据库(如 Amazon RDS和 Oracle Cloud)兼容,并支持本地或远程 Oracle服务器。
9、Navicat for SQLite(关系型数据库):它是一个强大而全面的 SQLite图形用户界面,它提供了一套完整的数据库管理和开发功能。优化你的 SQLite工作流程和生产力-你可以快速、安全地创建、组织、访问和共享信息。
三、mpp架构数据库有哪些
1、MPP架构,即大规模并行处理架构,其数据库产品中的一些代表作包括 Vertica、Redshift(原为Paracel,后被Amazon收购并改名为Redshift)和 Greenplum。它们之间的共同点显著:
2、首先,它们都源于PostgreSQL,这是一种强大的开源关系型数据库管理系统,它们共享了PostgreSQL的基础架构。
3、其次,它们采用列式存储技术,也称为列式数据库,这种存储方式优化了对大量数据的处理,尤其在大数据场景下,提升了数据读取和分析的效率。
4、最后,这些MPP数据库的核心操作都基于扫描原理,通过压缩技术来提升性能。这种设计使得它们在处理海量数据时,能够实现高效的并发处理和资源利用。
5、总结来说,MPP架构数据库如Vertica、Redshift和Greenplum,都是建立在PostgreSQL基础上,采用列式存储和扫描操作,通过压缩技术来优化大规模数据处理性能的解决方案。