在UltraEdit中使用正则表达式
发布时间:2025-05-20 09:55:45 发布人:远客网络
一、在UltraEdit中使用正则表达式
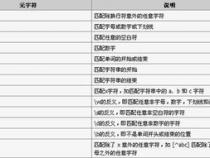
%匹配行首-表明要搜索的字符串一定在行首.
$匹配行尾-表明要搜索的字符串一定在行尾
?匹配除换行符外的任一单个字符.
*匹配任意个数的字符出现任意次数(不包括换行符)
+匹配前导字符或者表达式出现一次或者更多次(不包括换行符)
++匹配前导字符或者表达式不出现或者出现一次以上(不包括换行符)
^r匹配MAC文件的换行符(CR Only)
^n匹配UNIX文件的换行符(LF Only)
删除行尾空格:替换 [ ^t]+$为空串
删除行首空格:替换%[ ^t]+为空串
每行设置为固定的4个空格开头:替换%[ ^t]++^([~ ^t^p]^)为" ^1"
每段设置为固定的4个空格开头:替换%[ ^t]+为""
(如果一行是以空格开始的,则视之为一段的开始行)
将一段合并为一行:替换 [ ^t]++^p^([~ ^t^p]^)为 ^1
(注意:此处假定文本是以DOS方式回车换行- CR/LF)
去掉HTML TAG:替换 ^{*^}^{*^p*^}为空串
删除HTML中的所有A:替换 [ ]++a*[ ]++href[ ]++=*为空串
删除文本中指定的前2列字符:替换%??为空串
在第4列后插入2列空白字符:替换%^(????^)^(?^)为"^1 ^2"
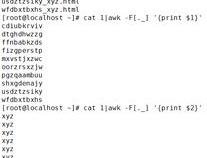
查找所有的数字: [0-9]+[.]++[0-9]+
查找所有的网址: http://[a-z0-9^~`_./^-^?=]+
注意:替换的时候需要勾选使用正则表达式选项
在UltraEdit配置中的正则表达式引擎中挑上使用UltraEdit风格,13版本使用Unix风格不能使用正则表达式分组功能
从Ultraedit8.0一直使用到现在,感觉这个东东确实不错。现将一些基本的经验总结如下,与大家共享;欢迎有兴趣的朋友前来补充。
Tip 0:没有注册码,如何有效使用Ultraedit呢?
很多人立即想到使用crack版,可实际追究起来,那是违法的事情。实际上,Ultraedit并没有把路子完全堵死。我们可以使用一些小技巧来屏蔽掉这个问题。修改ultraedit的快捷方式,将命令行改为:E:uedit9UEDIT32.EXE p:,其中p:必须是你的机器上不存在的分驱,这样,就不会有试用时间结束的问题了。
Tip 1:如何去掉所编辑文本中包含特定字符串的行?
这则技巧是在UltraEdit的帮助文件里提到.CTRL+R调出来替换(Replace)窗口,选中"使用正则表达式";然后用查找%*你的字符串*^p替换成空内容即可.如,我当前有个文本文件,需要去掉所有包含 这个字符串的行,查找%**^p替换成空即可.注意,^p是 DOS文件类型的换行符.如果是 Unix类型文件,则用 ^n.
Tip 2:如何在行末添加特定字符,比如逗号?
有了上面的经验(其实我第一次是从同事那里学到的),CTRL+R调出来替换(Replace)窗口,选中"使用正则表达式".然后可以查找 ^p(或者^n,如果是Unix文件),用,^p(或者,^n)进行"全部替换"即可.补充一点,如果是 MAC(Apple)类型文件,则换行符号为 ^r.
参考上面两个例子,查找 ^p$然后替换为空即可.
看来,正则表达式需要学习一下喽.
Tip 5:为何拷贝(Copy)/粘贴(Paste)功能不能用了?
不怕大家笑话,我有几次使用 UltraEdit的过程中发现拷贝与粘贴的内容是不匹配的.不知所以然,干脆重新启动了笔记本.今天翻看手册才恍然大悟:UltraEdit有10个剪切板(clipboard),分别用Ctrl+0- Ctrl+9切换. Ctrl+0是Windows的,其他则为用户自定义的.我在使用的过程中错调用了 CTRL+n,结果内容就有问题了.你遇到过没?
Tip 6:即使是打开小文件也有迟延?
这是我遇到过的问题.每次打开文件的时候总有几秒钟的耽搁.我的机器性能可不算差.怎么回事?网络打印机搞得鬼!打开"高级"-"设置"-"编辑器"-"高级",看看是不是选中了"载入/恢复打印机设置"?如果是的话,去掉(不同的版本/汉化与否可能该位置所在有差别).
Tip 8:你按一下快捷键ALT+c试试,变为列编辑模式,可以一次输入多行内容,只要你选好行范围,编辑整齐的数据表非常合适。
Tip 9:光标位于某一行,按Ctrl+F2试试,有了标签了,多设几个,按住F2,它会往你设定的标签处跳来跳去,很好玩。
Tip 10:暂时没想出来,有兴趣的前来补充。
--如何在UltraEdit中配置Java编译器和运行指令:
方法:在Advanced-- Tool configuration菜单的对话框里
在command line里输入:c:jdk1.3binjavac%f
注意:这里的javac路径你要按你自己的来指定;%f是指当前活动文档的全文件名,即“文件名.扩展名",
因为java程序在编译时必须带上扩展名。如果你用了%F(大写)是不对的,它只表示文件名而不带扩展名
(对于java运行命令是这样的)。在Menu Item Name里输入javac,它出现在菜单里,这样你就知道它是
用来编译的。然后选择output to list box和 capture output,这样当编译错误的时候你就可以在源代码
的下面的output窗口里看到错误信息了。
在command line里输入:java%n,或者java%F,这两个有时候不一样,看你的环境怎么配置了,我是使用的前一个。
在Menu Item Name里输入: java-no parameter
并且选择output to list box和 capture output,这样当运行的时候,运行结果显示在output窗口里。
在command line里输入:java%n%modify%
在Menu Item Name里输入: java-parameter,这样当你运行的时候,它会有一个对话框要求你输入参数
很多朋友都用过或者正在用UltraEdit,这个编辑器陪伴我也好几年了,从很多地方影响着我写代码的快捷键习惯,Ultraedit提供了非常丰富的编辑功能,其中非常重要的查找和替换功能一定大家都用过,Ultraedit提供的查找替换功能非常方便和强大,可以在单独文件里面查找替换,也可以在多个文件、多个目录里面进行查找替换。而我们在使用这些查找替换功能的时候,一般都是针对某个字符串进行,前两天我要对一个目录下(包含子目录)所有的html文件中某一段代码进行查找替换,一下子不知道怎么操作了,由于长期写程序用到正则表达式,于是猜想具备如此强大功能的Ultraedit一定也有这样类似的匹配功能,于是点击Help一看,果然不出所料,Ultraedit支持基本的正则表达式匹配查找和替换功能,这能满足我们几乎全部的需要了。
下面是对UltraEdit的Help中针对查找替换使用正则表达式部分的整理,最后还有我前两天用到的一个多行代码查找替换的例子。
Ultraedit在使用正则表达式进行查找替换时有两个可使用的语法集合。一个是 UltraEdit的更早的版本被使用的原来的 UltraEdit句法。另一个是”Unix”类型的正则表达式,这个集合在ultraedit的默认配置中是没有启用的,需要在配置中找到search项,启用Unix类型的正则表达式。
%匹配行的开始-显示搜索字符串必须在行的开始,但是在所选择的结果字符串中不包括任何行终止字符。
$匹配行尾-显示搜索字符串必须在行尾,但是在所选择的结果字符串中不包括任何行终止字符。
?除了换行符以外匹配任何单个的字符
*除了换行符匹配任何数量的字符和数字
+前一字符匹配一个或多个,但至少要出现一个
++前一字符匹配零个或多个,但至少要出现一个
^p匹配一个换行符(CR/LF)(段)(DOS文件)
^r匹配一个换行符(CR仅仅)(段)(MAC文件)
^n匹配一个换行符( LF仅仅)(段)( UNIX文件)
[]匹配任何单个的字符,或在方括号中的范围
^(^)括或标注为用于替换命令的表达式。
一个正则表达式最多可以有9个标注表达式,按正规表达式的需要而定。
相应的替换表达式是 ^x,替换范围x是1-9。例如:
If ^(h*o^) ^(f*s^) matches“hello folks”,
^2 ^1 would replace it with“folks hello”.
(hello folks将被替换成 folks hello。)
注: ^是实际字符 ^不是Ctl+键值。
m?n匹配“man”,”men”,”min”但不匹配“moon”.
t*t匹配“test”,”tonight”和“tea time”(the“tea t” portion)但不匹配“tea
time”(newline between“tea” and“time”).
Te+st匹配“test”,”teest”,” teeeest“等等。但是不匹配“tst”。
[,.?]匹配一文字的“,”,”.”或“?”。
[0-9, a-z]匹配任何数位,或小写字母。
[~0-9]除了数字以外匹配任何字符(~意味着”不”)
你按如下方式可以查找一个表达式A或 B:
这将在找John或Tom的出现。应该在 2个表达式之间没有任何东西。
你可以在同一搜索中按如下方式组合A or B and C or D:
“^{John^}^{Tom^}^{Smith^}^{Jones^}”
这将在John or Tom后面找 Smith or Jones。
语法二:”Unix”句法类型的正则表达式
/标记下一个字符作为一个特殊的字符。
"n"匹配字符"n"。"n"一个换行符或换行符字符。
.匹配除了一个换行符字符匹配任何单个的字符。
(expression)标注用于替换命令的表达式。一个正则表达式根据需要,最多可以有9个标注表达式。相应的代替表达式是 x, x的范围是 1-9。
If(h.*o)(f.*s) matches“hello folks”,
2 1 would replace it with“folks hello”.
(hello folks将被替换成 folks hello。)
[xyz]一个字符集。匹配在方括号之间的任何字符。
[^xyz]一个否定的字符集。不匹配在方括号之间的任何字符。
/d匹配一个数字字符。等价于[0-9]。
/D匹配一个非数字字符。等价于[^0-9]。
/s匹配任何空白的空格,标签,换页,包括空格等等,但不匹配换行符。
/S匹配任何非空白的字符,但不匹配换行符。
/w匹配任何词语字符包括下划线。
注: ^是实际字符 ^不是Ctl+键值。
m.n匹配“man”,”men”,”min”但不匹配“moon”.
t+t匹配“test”,”tonight”和“tea time”(the“tea t” portion)但不匹配“tea
time”(newline between“tea” and“time”).
Te*st匹配“test”,”teest”,” teeeest“等等。但是不匹配“tst”。
[,.?]匹配一文字的“,”,”.”或“?”。
[0-9,a-z]匹配任何数位,或小写字母。
[^0-9]除了数字以外匹配任何字符(~意味着”不”)
你按如下方式可以查找一个表达式A或 B:
这将在找John或Tom的出现。应该在 2个表达式之间没有任何东西。
你可以在同一搜索中按如下方式组合A or B and C or D:
这将在John or Tom后面找 Smith or Jones。
p匹配 CR/LF(作为 rn的一样)作为DOS行结束符匹配
如果查找/替换功能中正则表达式没有选用,则替换字段中下列字符也是有效的:
^s替换为被选择(加亮)活跃的文件窗口的文章。
^p匹配一个换行符( CR/LF)(段)( DOS文件)
^r匹配一个换行符( CR仅仅)(段)( MAC文件)
^n匹配一个换行符( LF仅仅)(段)( UNIX文件)
下面是我要实现的一段代码查询替换的举例
有这样一段代码分布在各个html文件中
!-- Copyright?2005. toplee Ltd--
A.applink:hover{border: 2px dotted#DCE6F4;padding:2px;background-color:#ffff00;color:green;text-decoration:none}
A.applink{border: 2px dotted#DCE6F4;padding:2px;color:#2F5BFF;background:transparent;text-decoration:none}
A.info{color:#2F5BFF;background:transparent;text-decoration:none}
A.info:hover{color:green;background:transparent;text-decoration:underline}
div style='BORDER: 1px solid#DCE6F4; MARGIN-TOP: 20px; MARGIN-BOTTOM: 20px; MARGIN-LEFT: 5px;
!--/Copyright?2005. toplee Ltd--
我要把上面一段代码替换为空,于是编写下面的匹配规则
每行设置为固定的4个空格开头:替换%[^t]++^([~^t^p]^)为”^1″
每段设置为固定的4个空格开头:替换%[^t]+为”"
(如果一行是以空格开始的,则视之为一段的开始行)
将一段合并为一行:替换[^t]++^p^([~^t^p]^)为^1
(注意:此处假定文本是以DOS方式回车换行-CR/LF)
去掉HTMLTAG:替换^{*^}^{*^p*^}为空串
删除HTML中的所有:替换[]++a*[]++href[]++=*为空串
删除文本中指定的前2列字符:替换%??为空串
在第4列后插入2列空白字符:替换%^(????^)^(?^)为”^1^2″
查找所有的数字:[0-9]+[.]++[0-9]+
查找所有的网址:http://[a-z0-9^~`_./^-^?=]+
注意:替换的时候需要勾选使用正则表达式选项
二、UltraEdit+删除空行的正则表达式
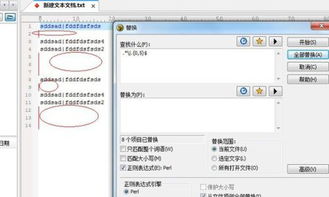
1、首先使用UltraEdit打开文件,选择搜索(Search)菜单的替换(Replace)命令。在替换对话框中,选中正则表达式(E):UltraEdit复选框,并在查找中输入:%[ ^t]++^p,注意^t之前有空格。该表达式字符含义与EditPlus的相对应。
2、然后,单击开始按钮,进行替换删除空行。
3、 匹配行首-表示搜索字符串必须在行首,但不包括任何选定的结果字符中的行终止字符。
4、 匹配行尾-表示搜索字符串必须在行尾,但不包括任何选定的结果字符中的行终止字符。
5、 匹配任何除换行符的字符。
6、 匹配任何除换行符外所出现的任意数量的字符。
7、 匹配一个或多个前面的字符/表达式。必须找到至少一个出现的字符。不匹配重复的换行符。
8、 0次或多次匹配前面的字符/表达式。不匹配重复的换行符。
9、 匹配一个分页符。
10、 匹配一个换行符(CR/LF)(段落)(DOS文件)
11、 匹配一个换行符(仅 CR)(段落)(MAC文件)
12、 匹配一个换行符(仅 LF)(段落)(UNIX文件)
13、 匹配一个制表符
14、 匹配任何括号中的单个字符或范围
15、 匹配表达式 A或 B
16、 忽略其后的正则表达式字符
17、 在表达式加上括号或标签在替换命令中使用。正则表达式中可以有 9个表达式标签,数字根据它们在正则表达式中的次序确定数字。
18、相应的替换表达式是 ^x,x的范围是 1-9。例如:如果 ^(h*o^) ^(f*s^)匹配“hello folks”,那么^2 ^1表示将用“folks hello”替换它。
19、注意- ^这里涉及的字符“^”不是控制键+值。
20、m?n匹配“man”、“men”、“min”,但不匹配“moon”。
21、t*t匹配“test”、“tonight”和“tea time”中的“tea t”部分,但不匹配“tea
22、time”(“tea”和“time”之间有换行)。
23、Te+st匹配“test”、“teest”、“teeeest”等,但不匹配“tst”。
24、[,.?]匹配文字“,”、“.”或“?”。
25、[0-9a-z]匹配任何数字或小写字母
26、[~0-9]匹配除数字外的任何字符(~表示不匹配其后的内容)
27、你可以搜索象下面一样的表达式 A或 B:
28、这将搜索 John或 Tom。在两个表达式之间应该没有任何其它内容。
29、你可以在同一次搜索象下面一样组合 A或 B和 C或 D:
30、"^{John^}^{Tom^} ^{Smith^}^{Jones^}"
31、这将搜索后面跟随了 Smith或 Jones的 John或 Tom。
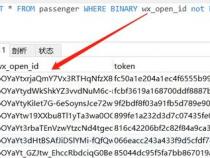
三、ultraedit正则表达式能不能匹配汉字
1、分类:电脑/网络>>程序设计>>其他编程语言
2、请问ultraedit中的正则表达式可以匹配汉字吗?
3、如果要匹配任意个汉字,应该怎么写?
4、\u0000后面是四位十六位数字
5、如果你对汉字的unicode不熟悉,请搜汉字编码查询,就搞定了
6、一些文本编辑工具都直接可以用于中文的正则表达式的匹配