如果网页内容是由javascript生成的,应该怎么实现爬虫
发布时间:2025-05-19 22:37:19 发布人:远客网络
一、如果网页内容是由javascript生成的,应该怎么实现爬虫
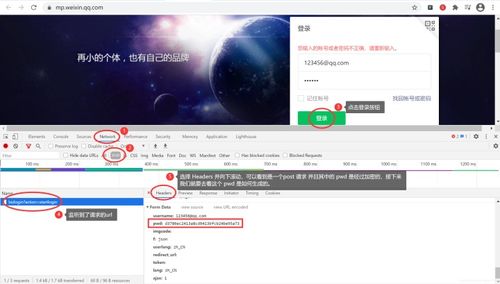
对于提到的两种方法,抓包分析获取请求的参数和驱动浏览器内核执行 js代码,两种方法各有优点,选择适合你的方式就好。
抓包分析,这个方法的优点是抓取的速度快,取得数据结构比较好,处理起来简单,很多是 json格式的数据,但是抓包分析需要大量的时间,这里的时间是指需要模拟需要获取数据的之前的一个或者几个请求,涉及到 headers里的很多参数,有时候还设计到数据加密,这个过程你可能需要读 js源码,才能解决问题。所以这个方式适合那些请求参数较少,数据结构比较好的网站。
2.驱动浏览器内核,这个方法的优点是编程实现比较简单,只要学会了驱动浏览器的 api就可以在很少的改动下用于很多不同网站的抓取。但是缺点也很明显,慢,占用的资源比较多,不如抓包分析获取数据灵活。
我以前抓取的好多网站都是用抓包分析的方式,还分析了好多网站的登录的机制,用 Python重写 js的请求,做模拟登录,对于抓包分析有些偏执,但是我现在的观点是:用最少的时间成本来解决问题,这里的时间成本是指编程时间和抓取的时间之和。当然你如果是学习的话,我建议两种方式都学。
二、爬虫请求头怎么设置支持javascript
在进行爬虫时,如果要支持JavaScript,可以通过在请求头中添加相应的字段来实现。具体步骤如下:
1.引入requests库,用于发送HTTP请求。
2.创建一个字典,用于保存请求头信息。
3.在请求头中添加"User-Agent"字段,设置为常用的浏览器的User-Agent字符串,以模拟浏览器发送请求。
4.在请求头中添加"Accept"字段,设置为"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",指定服务器返回的响应类型。
5.在请求头中添加"Referer"字段,设置为页面的URL地址,用于标识请求来源。
6.在请求头中添加"Accept-Language"字段,设置为"zh-CN,zh;q=0.9,en;q=0.8",指定浏览器的语言偏好。
7.在请求头中添加"Connection"字段,设置为"keep-alive",实现持久连接。
8.发送HTTP请求时,将请求头字典作为headers参数传入requests库的get或post方法中。
需要注意的是,支持JavaScript的爬虫需要使用无头浏览器,如Selenium或Pyppeteer等库,来解析动态生成的内容。这些库会模拟用户在浏览器中操作的行为,并渲染JavaScript,将最终的页面内容返回给爬虫。
如果无需执行JavaScript,只需获取静态页面内容,可以直接发送HTTP请求获取页面内容,无需额外设置请求头。
三、学习python爬虫可以练习爬哪些网站
学习Python爬虫可以练习爬取的网站多种多样,以下列举几类常见且具有挑战性的网站:
1.视频网站如B站(Bilibili):这类网站数据结构复杂,不仅包括视频内容,还有弹幕、评论等多种互动元素。通过爬虫获取弹幕、评论等信息,不仅需要理解网页结构,还要应对网站的反爬机制,如本例所示。
2.社交媒体平台如微博、知乎:这类网站上的信息丰富多样,包括用户动态、文章、问答等,需要熟练掌握解析复杂HTML结构、处理JavaScript动态加载内容等技巧。
3.电商网站如淘宝、京东:这类网站上的商品信息丰富且更新频繁,通过爬虫可以获取商品详情、价格、评价等数据,对数据抓取和处理能力要求较高。
4.新闻网站如CNN、BBC:这类网站提供实时新闻和深度报道,通过爬虫获取新闻标题、摘要、发布时间等信息,有助于快速掌握信息。
5.音乐网站如网易云音乐、QQ音乐:这类网站提供音乐资源,通过爬虫可以获取歌曲信息、评论、用户评分等,需要掌握HTML解析和API调用等技术。
6.学术资源网站如Google Scholar、PubMed:这类网站提供学术论文资源,通过爬虫可以获取论文标题、作者、摘要、引用次数等信息,对网页解析和数据提取能力要求较高。
通过练习爬取这些网站的数据,可以提升Python编程、网络爬虫技术、数据解析和处理能力,同时深入了解各网站的结构和数据特点。