b(<word>w+)s+(k<word>)b 正则表达式
发布时间:2025-05-19 18:55:21 发布人:远客网络

一、\b(<word>\w+)\s+(\k<word>)\b 正则表达式
1、转义字符\b是一个特例。在正则表达式中,\b表示单词边界(在\w和\W之间),不过,在 []字符类中,\b表示退格符。在替换模式中,\b始终表示退格符。
2、将匹配的子表达式捕获到一个组名称或编号名称中。用于 name的字符串不得包含任何标点符号,并且不能以数字开头。可以使用单引号替代尖括号,例如(?'name')。
3、与任何空白字符匹配。等效于转义符和 Unicode通用类别 [\f\n\r\t\v\x85\p{Z}]。如果通过 ECMAScript选项指定了符合 ECMAScript的行为,则\s等效于 [\f\n\r\t\v]。
4、命名后向引用。例如,(?<char>\w)\k<char>查找双写的单词字符。表达式(?<43>\w)\43执行同样的操作。可以使用单引号替代尖括号,例如\k'char'。
5、\b(?<word>\w+)\s+(\k<word>)\b
6、这句话的意思是,匹配两个连续两个中间有空格(空白)的单词。
二、word和正则表达式
Word的查找替换功能,原来还能支持正则表达式,真是让人惊喜不已。本文将分享如何利用 Word中的正则表达式,实现对文本中多余换行符的替换。这次的目标是替换掉.txt文件中因格式转换而产生的额外换行符,同时保持原有分段不被破坏。
在替换规则上,如果换行符后面紧跟非换行符字符,说明这一行内容应保留,需删除该换行符;但若两个换行符紧挨着出现,则只保留一个换行符。
尝试了多种正则表达式,例如使用"^p"替换两个换行符为一个,但这方法在“使用通配符”模式下无法直接使用,且无法使用小括号。这里必须借助小括号来区分查找字符串的两部分,确保只删除一个换行符,保留后续字符。
在“使用通配符”模式下区分连续两个换行符与一个换行符,确实存在困难。尝试了括号、方括号、以及常见的通配符(^、$、*、.)等,都无法满足需求。最终,通过上述方法解决了问题。
保存替换前的文本副本以防丢失。
Word查找栏与替换栏代码·通配符一览表
查找与替换代码中的通配符用法详解
1.任意单个字符:“?”可以代表任意单个字符,多个“?”表示多个未知字符。如:输入“?国”可找到“中国”、“美国”等;输入“???国”可找到“孟加拉国”。
2.任意多个字符:“*”表示任意多个字符。输入“*国”可找到“中国”、“美国”等。
3.指定字符之一:“[]”框内字符代表要查找的特定字符之一。如:输入“[中美]国”可找到“中国”、“美国”;输入“th[iu]g”可找到“thigh”、“thug”;输入“[学硕博]士”可查到“学士”、“硕士”、“博士”;输入“[大中小]学”可查到“大学”、“中学”或“小学”。
4.指定范围内的任意单个字符:“[x-x]”表示指定范围内的任意单个字符,范围需升序。如:输入“[a-e]ay”可找到“bay”、“day”等;输入“[a-c]mend”可找到“amend”、“bmend”、“cmend”。
5.排除指定范围内的任意单个字符:“[!x-x]”排除特定范围内的字符,如:输入“[!c-f]”可找到“bay”、“gay”等,但不包括“cay”、“day”;输入“[!a-c]”可找到“good”、“see”、“these”。
6.指定前一字符个数:“{n}”表示前一字符出现的次数,如:“cho{1} se”表示查找包含1个“o”的“chose”;“cho{2}se”表示查找包含2个“o”的“choose”。
7.指定前一字符数范围:“{x,x}”表示前一字符数的范围,如:“cho{1,2}”表示查找包含1-2个“o”的“chose”或“choose”。
8.一个以上前一字符:“@”表示查找包含一个以上前一字符的文本,如:“cho@se”可找到“chose”、“choose”。
9.指定起始字符串:“<”表示查找文本的起始字符串,如:“<江山>”表示查找以“江山”开头的文本。
10.指定结尾字符串:“>”表示查找文本的结尾字符串,如:“er>”表示查找以“er”结尾的文本。
11.表达式查找:“()”用于多个关键词组合查找,如:“(America)(China)”可将“China America”替换为“America China”。
联合使用通配符以增加精确度,例如:“<(ag)*(er)>”表示查找所有以“ag”开头且以“er”结尾的单词。记得在字符前添加反斜杠“\”来查找特殊字符,如:“\*”表示查找字符“*”。
利用通配符进行搜索时,选中“使用通配符”选项后,Word将只查找精确匹配的文本。若要查找已被定义为通配符的字符,如“*”、“?”等,需在字符前键入反斜杠“\”。
在“查找内容”或“替换为”框中使用的代码与通配符选项的设置相关。确保了解如何在不同搜索场景下使用正确的代码。
例子:将 word文档中相邻的两个数字间都加入 tab制表位。查找正则表达式:([0-9])([0-9]),替换正则表达式:\1^t\2。记得在 Word中使用正则替换时,分组引用方式为“\n”(n为分组编号)。
三、word的正则匹配文档序号
在word中能够实现自动连续编号这一功能的域有AutoNum、AutoNumLgl、AutoNumOut和ListNum等。前三个域仅可以实现每个段落的连续编号,不能实现段落内每个句子的连续编号,且不能调整编号开始的数字。在同一个文档内,AutoNum、AutoNumLgl和AutoNumOut三个域之间是相互影响的,如前面几段使用了AutoNum域进行编号,后面使用AutoNumLgl域进行编号,后面的编号是接续前面AutoNum域的编号的,不是重新开始的。ListNum可以实现文档内每个句子的自动连续编号。ListNum是一种多级列表域,有四种内置列表。域代码与相应的输出如下。
(1)、{ LISTNUM l 1}——输出内置默认列表的一级编号“1)”
(2)、{ LISTNUM LegalDefault l 1}——输出输出内置LegalDefault列表的一级编号“1.”
(3)、{ LISTNUM NumberDefault l 1}——输出输出内置NumberDefault列表的一级编号“1)”
(4)、{ LISTNUM OutlineDefault l 1}——输出输出内置OutlineDefault列表的一级编号“I.”
ListNum域,可以在任意位置设置编号重新以任意数字开始,编号的样式也比较多,而且是多级的编号,使用起来是很方便的。
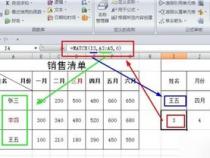
所以使用第(2)个域代码可以实现上图所示的编号功能。
首先使用快捷键Ctrl+F9,输入一对域代码专用的大括号,然后将代码LISTNUM LegalDefault l 1写入大括号内,按F9刷新即可得到域结果1.。
如果文档内容较少,那么我们可以手动复制这个域到其他位置,即可实现连续自动编号。
但文档内容多,我们需要将此域用于查找替换对话框中,以实现批量替换。
由于不能直接复制域代码放入替换框中,所以我们输入了第一个域代码后,需要将其剪切,然后在替换框中使用“^c”(剪贴板内容)来代替它。
能够实现查找每一句话的正则表达式
接下来,只要在“查找和替换”对话框中,批量查找每一个句子,并在其前面加上这个域代码即可。根据每个句子总是以文字开头,并以特定的几个标点结尾,写出如下表达式:
查找内容:([!^13^l]*[.?!。!?……])
最后点击“全部替换”即可完成整篇文档每个句子的自动连续编号。