如何用python实现随机森林分类
发布时间:2025-05-18 11:16:51 发布人:远客网络
一、如何用python实现随机森林分类
大家如何使用scikit-learn包中的类方法来进行随机森林算法的预测。其中讲的比较好的是各个参数的具体用途。
这里我给出我的理解和部分翻译:
最主要的两个参数是n_estimators和max_features。
n_estimators:表示森林里树的个数。理论上是越大越好。但是伴随着就是计算时间的增长。但是并不是取得越大就会越好,预测效果最好的将会出现在合理的树个数。
max_features:随机选择特征集合的子集合,并用来分割节点。子集合的个数越少,方差就会减少的越快,但同时偏差就会增加的越快。根据较好的实践经验。如果是回归问题则:
max_features=n_features,如果是分类问题则max_features=sqrt(n_features)。
如果想获取较好的结果,必须将max_depth=None,同时min_sample_split=1。
同时还要记得进行cross_validated(交叉验证),除此之外记得在random forest中,bootstrap=True。但在extra-trees中,bootstrap=False。
这里也给出一篇老外写的文章:调整你的随机森林模型参数
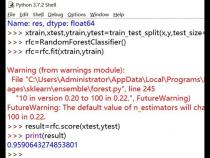
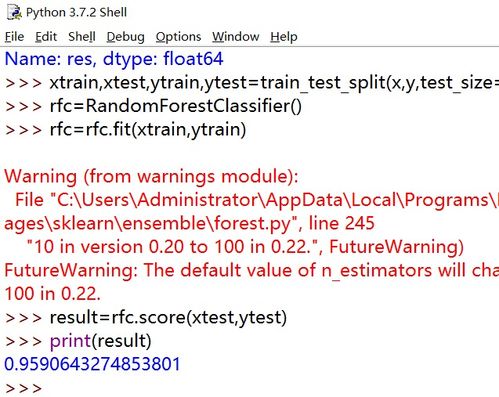
这里我使用了scikit-learn自带的iris数据来进行随机森林的预测:
fromsklearn.treeimportDecisionTreeRegressor
fromsklearn.ensembleimportRandomForestRegressor
fromsklearn.datasetsimportload_iris
#printiris#iris的4个属性是:萼片宽度萼片长度花瓣宽度花瓣长度标签是花的种类:setosaversicolourvirginica
printiris['target'].shape
rf=RandomForestRegressor()#这里使用了默认的参数设置
rf.fit(iris.data[:150],iris.target[:150])#进行模型的训练
print'instance0prediction;',rf.predict(instance[0])
print'instance1prediction;',rf.predict(instance[1])
printiris.target[100],iris.target[109]
在这里我有点困惑,就是在scikit-learn算法包中随机森林实际上就是一颗颗决策树组成的。但是之前我写的决策树博客中是可以将决策树给显示出来。但是随机森林却做了黑盒处理。我们不知道内部的决策树结构,甚至连父节点的选择特征都不知道是谁。所以我给出下面的代码(这代码不是我的原创),可以显示的显示出所有的特征的贡献。所以对于贡献不大的,甚至是负贡献的我们可以考虑删除这一列的特征值,避免做无用的分类。
fromsklearn.cross_validationimportcross_val_score,ShuffleSplit
score=cross_val_score(rf,X[:,i:i+1],Y,scoring="r2",
scores.append((round(np.mean(score),3),names[i]))
printsorted(scores,reverse=True)
[(0.934,'petal width(cm)'),(0.929,'petal length(cm)'),(0.597,'sepal length(cm)'),(0.276,'sepal width(cm)')]
这里我们会发现petal width、petal length这两个特征将起到绝对的贡献,之后是sepal length,影响最小的是sepal width。这段代码将会提示我们各个特征的贡献,可以让我们知道部分内部的结构。
二、如何利用Python进行垃圾分类
七月了,大家最近一定被一项新的政策给折磨的焦头烂额,那就是垃圾分类。《上海市生活垃圾管理条例》已经正式实施了,相信还
是有很多的小伙伴和我一样,还没有完全搞清楚哪些应该扔在哪个类别里。感觉每天都在学习一遍垃圾分类,真令人头大。
听说一杯没有喝完的珍珠奶茶应该这么扔
1、首先,没喝完的奶茶水要倒在水池里
2、珍珠,水果肉等残渣放进湿垃圾
4、接下来是盖子,如果是带盖子带热饮(比如大部分的热饮),塑料盖是可以归到可回收垃圾的嗷
看到这里,是不是大家突然都不想喝奶茶了呢,哈哈。不过不要紧,垃圾分类虽然要执行,但是奶茶也可以照喝。
那么,这里我们想讨论一下,人工智能和数据科学的方法能不能帮助我们进行更好的垃圾分类?这样我们不用为了不知道要扔哪个垃
这问题的解决思路或许不止一条。这里只是抛砖引玉一下,提供一些浅显的见解。
第一种方案,可以把垃圾的信息制成表格化数据,然后用传统的机器学习方法。
第二种方案,把所有的垃圾分类信息做成知识图谱,每一次的查询就好像是在翻字典一样查阅信息。
第三种方案,可以借助现在的深度学习方法,来对垃圾进行识别和分类。每次我们给一张垃圾的图片,让模型识别出这是属于哪一种
类别的:干垃圾,湿垃圾,有害垃圾还是可回收垃圾。
图像分类是深度学习的一个经典应用。它的输入是一张图片,然后经过一些处理,进入一个深度学习的模型,该模型会返回这个图片
里垃圾的类别。这里我们考虑四个类别:干垃圾,湿垃圾,有害垃圾还是可回收垃圾。
我们对图片里的物品进行分类,这是图像处理和识别的领域。人工智能里提出了使用卷积神经网络(Convolutional Neural Network, CNN)来解决这一类问题。
我会用keras包和Tensorflow后端来建立模型。由于训练集的样本暂时比较缺乏,所以这里只能先给一套思路和代码。训练模型的工
我们就先来看看代码大致长什么样吧
在上面,我们初始化了一些变量,batch size是128; num_classes= 4,因为需要分类的数量是4,有干垃圾,湿垃圾,有害垃圾
回收垃圾这四个种类。epochs是我们要训练的次数。接下来,img_rows, img_cols= 28, 28我们给了图片的纬度大小。
在.reshape(60000,28,28,1)中, 60000是图片的数量(可变), 28是图片的大小(可调),并且1是channel的意思,channel= 1
是指黑白照片。.reshape(10000,28,28,1)也是同理,只是图片数量是10000。
到了最后两行,我们是把我们目标变量的值转化成一个二分类,是用一个向量(矩阵)来表示。比如 [1,0,0,0]是指干垃圾,[0,1,0,0]
我们加了卷积层和池化层进入模型。激活函数是 relu,relu函数几乎被广泛地使用在了卷积神经网络和深度学习。我们在层与层之间
也加了dropout来减少过拟合。Dense layer是用来做类别预测的。
建完模型后,我们要进行模型的验证,保证准确性在线。
到这里,我们的建模预测已经大概完成了。一个好的模型,要不断地去优化它,提高精确度等指标要求,直到达到可以接受的程度。
这优化的过程,我们在这里就先不深入讨论了,以后继续。
值得一提的是,尽管方法上是有实现的可能,但是实际操作中肯定要更复杂的多,尤其是对精度有着很高的要求。
而且当一个图片里面包含着好几种垃圾种类,这也会让我们的分类模型开发变得很复杂,增加了难度。
比如,我们想要对一杯奶茶进行垃圾分类,照片里面是包含了多个垃圾的种类,这就比较头大了,因为这并不是属于单一的类别。
前路的困难肯定是有的,不过就当这里的分享是个抛砖引玉的起点吧。
毕竟李白也说了,“长风破浪会有时,直挂云帆济沧海”。
三、详细讲解Python的数字分类
1、在讲解Python数字分类前,我们先来明确一些概念。在unicode字符集中,数字被分为三类:numeric、digit和decimal。其中,decimal是最为明确的,它指的是所有语言书写体系的十进制数。然而,numeric和digit在中文表达上不够直白,但通过实例可以一目了然。
2、我们用一些实例来展现它们的区别与联系。例如,`str.isdecimal()`函数用于判断字符串中的字符是否全为十进制数字,且至少有一个字符。在Python中,它能准确识别任何书写体系下的十进制数字。
3、而`str.isdigit()`函数的判定条件稍显严格,它要求字符串中的字符全部为数字,且至少有一个字符。数字的概念在这里不仅限于十进制,还包括了所有数字字符。
4、`str.isnumeric()`则更为宽泛,它判断字符串中的字符是否全为numeric类,且至少有一个字符。numeric类包括了所有具有特定属性的数字字符,如前面提及的decimal和digit,还有其他一些独特的数字。
5、`str.isalpha()`函数则用于判断字符串是否全由字母组成,至少包含一个字符。在Unicode字符集中,字母被定义为"Letter",包括了"Lm"、"Lt"、"Lu"、"Ll"或"Lo"属性的字符。
6、`str.isalnum()`函数的判定条件为字符串仅包含字母或数字,至少有一个字符。一个汉字在Python中是以Unicode编码形式存储,因此,包含汉字的字符串也会返回True。
7、这些函数的使用为我们提供了对字符串进行分类的能力,帮助我们更细致地处理数据。例如,我们可以利用这些函数来过滤数据,只保留特定类型的数据进行进一步处理。下面的图表展示了这些字符串类型的包含关系,直观地展示了它们之间的差异。
8、最后,虽然我在翻译上未能找到完美的中文对应,但对于数字的分类,通过实例和函数的应用,我们已经能够清晰地理解它们在Python中的功能与作用。希望这一内容能为你的编程之旅带来帮助,欢迎在评论区分享你的理解和应用经验。