cmd 命令怎么进入mysql数据库
发布时间:2025-05-18 07:05:38 发布人:远客网络
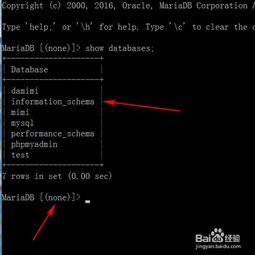
一、cmd 命令怎么进入mysql数据库
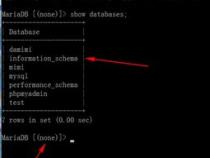
1、一般对于刚刚安装好的mysql,如果勾选启用mysql lineclient的话。可以直接通过找到开始---程序--- mysql command line client
2、点击mysql命令行之后,会提示你输入root密码。输入正确的root密码之后即可连接到msyql数据库里啦
3、如果没有安装mysql命令行的话,我们可以通过找到 mysqld所在的路径(复制mysqld.exe所在路径)
4、使用cd切换到msyqld.exe路径下,然后输入mysql连接命令如下图
Mysql-P端口号-h mysql主机名\ip-u root(用户)-p
5、如果是命令行是mysql所在的本机
而且用默认的端口 3306直接输入 mysql-u root-p即可
通过第三方数据库连接工具这些就很多啦,如下图设置好相关参数即可
7、连接进去之后,也就是比较人性化的图形界面了。
二、linux系统mysql数据库怎么进入数据库
linux系统进入mysql数据库的方法:
格式: mysql-h主机地址-u用户名-p用户密码
首先在打开DOS窗口,然后进入目录 mysqlbin,再键入命令mysql-uroot-p,回车后提示你输密码,如果刚安装好MYSQL,超级用户root是没有密码的,故直接回车即可进入到MYSQL中了,MYSQL的提示符是:mysql>
2、连接到远程主机上的MYSQL。假设远程主机的IP为:110.110.110.110,用户名为root,密码为abcd123。则键入以下命令:
mysql-h110.110.110.110-uroot-pabcd123(注:u与root可以不用加空格,其它也一样)
3、退出MYSQL命令: exit(回车)
一个建库和建表以及插入数据的实例:
create database school;//建立库SCHOOL
create table teacher//建立表TEACHER
id int(3) auto_increment not null primary key,//id设置为主关键字,并自动设值,也就是添加的时候,你不必向ID字段写内容
address varchar(50) default'深圳',//设置默值为深圳
insert into teacher values('','glchengang','建平一中','1976-10-10');//ID不用写内容
insert into teacher values('','jack','建平一中','1975-12-23');
三、MySQL的基本命令
进入:mysql-u root-p/mysql-h localhost-u root-p databaseName;
显示表格列的属性:show columns from tableName;
建立数据库:source fileName.txt;
匹配字符:可以用通配符_代表任何一个字符,%代表任何字符串;
增加一个字段:alter table tabelName add column fieldName dateType;
增加多个字段:alter table tabelName add column fieldName1 dateType,add columns fieldName2 dateType;
多行命令输入:注意不能将单词断开;当插入或更改数据时,不能将字段的字符串展开到多行里,否则硬回车将被储存到数据中;
增加一个管理员帐户:grant all on*.* to user@localhost identified by"password";
每条语句输入完毕后要在末尾填加分号';',或者填加'\g'也可以;
查询数据库版本:select version();
查询当前使用的数据库:select database();
1、删除student_course数据库中的students数据表:
rm-f student_course/students.*
2、备份数据库:(将数据库test备份)
mysqldump-u root-p test>c:\test.txt
备份表格:(备份test数据库下的mytable表格)
mysqldump-u root-p test mytable>c:\test.txt
将备份数据导入到数据库:(导回test数据库)
3、创建临时表:(建立临时表zengchao)
create temporary table zengchao(name varchar(10));
create table if not exists students(……);
5、从已经有的表中复制表的结构
create table table2 select* from table1 where 1<>1;
create table table2 select* from table1;
alter table table1 rename as table2;
alter table table1 modify id int unsigned;//修改列id的类型为int unsigned
alter table table1 change id sid int unsigned;//修改列id的名字为sid,而且把属性修改为int unsigned
alter table table1 add index ind_id(id);
create index ind_id on table1(id);
create unique index ind_id on table1(id);//建立唯一性索引
alter table table1 drop index ind_id;
11、联合字符或者多个列(将列id与":"和列name和"="连接)
select concat(id,':',name,'=') from students;
12、limit(选出10到20条)<第一个记录集的编号是0>
select* from students order by id limit 9,10;
事务,视图,外键和引用完整性,存储过程和触发器
<,<=,>=,>,=,between,in,不带%或者_开头的like
当查询优化器生成执行计划时,会考虑索引,太多的索引会给查询优化器增加工作量,导致无法选择最优的查询方案;
方法:在一般的SQL语句前加上explain;
2)type:连接的类型,(ALL/Range/Ref)。其中ref是最理想的;
3)possible_keys:查询可以利用的索引名;
5)key_len:索引中被使用部分的长度(字节);
6)ref:显示列名字或者"const"(不明白什么意思);
7)rows:显示MySQL认为在找到正确结果之前必须扫描的行数;
1)尽可能使用较短的数据类型;
a)用char代替varchar,固定长度的数据处理比变长的快些;
b)对于频繁修改的表,磁盘容易形成碎片,从而影响数据库的整体性能;
c)万一出现数据表崩溃,使用固定长度数据行的表更容易重新构造。使用固定长度的数据行,每个记录的开始位置都是固定记录长度的倍数,可以很容易被检测到,但是使用可变长度的数据行就不一定了;
d)对于MyISAM类型的数据表,虽然转换成固定长度的数据列可以提高性能,但是占据的空间也大;
尽量将列定义为not null,这样可使数据的出来更快,所需的空间更少,而且在查询时,MySQL不需要检查是否存在特例,即null值,从而优化查询;
如果一列只含有有限数目的特定值,如性别,是否有效或者入学年份等,在这种情况下应该考虑将其转换为enum列的值,MySQL处理的更快,因为所有的enum值在系统内都是以标识数值来表示的;
对于经常修改的表,容易产生碎片,使在查询数据库时必须读取更多的磁盘块,降低查询性能。具有可变长的表都存在磁盘碎片问题,这个问题对blob数据类型更为突出,因为其尺寸变化非常大。可以通过使用optimize table来整理碎片,保证数据库性能不下降,优化那些受碎片影响的数据表。 optimize table可以用于MyISAM和BDB类型的数据表。实际上任何碎片整理方法都是用mysqldump来转存数据表,然后使用转存后的文件并重新建数据表;
可以使用procedure analyse()显示最佳类型的建议,使用很简单,在select语句后面加上procedure analyse()就可以了;例如:
select* from students procedure analyse();
select* from students procedure analyse(16,256);
第二条语句要求procedure analyse()不要建议含有多于16个值,或者含有多于256字节的enum类型,如果没有限制,输出可能会很长;
第一次执行某条select语句时,服务器记住该查询的文本内容和查询结果,存储在缓存中,下次碰到这个语句时,直接从缓存中返回结果;当更新数据表后,该数据表的任何缓存查询都变成无效的,并且会被丢弃。
变量:query_cache _type,查询缓存的操作模式。有3中模式,0:不缓存;1:缓存查询,除非与 select sql_no_cache开头;2:根据需要只缓存那些以select sql_cache开头的查询; query_cache_size:设置查询缓存的最大结果集的大小,比这个值大的不会被缓存。
2)增加更快的硬盘以减少I/O等待时间;
寻道时间是决定性能的主要因素,逐字地移动磁头是最慢的,一旦磁头定位,从磁道读则很快;
3)在不同的物理硬盘设备上重新分配磁盘活动;
如果可能,应将最繁忙的数据库存放在不同的物理设备上,这跟使用同一物理设备的不同分区是不同的,因为它们将争用相同的物理资源(磁头)。