为什么java 7 开始在数字中使用下划线
发布时间:2025-05-14 04:09:30 发布人:远客网络
一、为什么java 7 开始在数字中使用下划线
JDK1.7的发布已经介绍了一些有用的特征,尽管大部分都是一些语法糖,但仍然极大地提高了代码的可读性和质量。其中的一个特征是介绍字面常量数字的下划线。从Java7开始,你就可以在你的Java代码里把长整型数字比如10000000000写成一个更具可读性10_000_000_000。在字面常量数字中加下划线的一个重要的原因是避免一些难以通过看代码来发现的细微的错误。对比10000000000和1000000000,我们很难发现少了一个0或多了一个0,但对于10_000_000_000和1_000_000_000却不然。所以如果你在Java源码中要处理大数字,你可以在数字中加入下划线来提高可读性。使用的时候要注意:在字面常量数字里加下划线是有一定规则的,下划线只能在数字之间,在数字的开始或结束一定不能使用下划线。在本章节的以下部分,我们将学习如何在字面常量数字中使用下划线,以及在字面常量数字中使用它们的规则。
怎样在Java中有效的给数字使用下划线
正如我之前说的,这不过是个语法糖,非常像字符串在 switch场景下的实现,这也是使用编译器的帮助下实现的。编译期间,编译器把这些下划线移除,并把真实的数字赋值给变量。比如在编译期间10_000_000将会被转化成10000000。既然CPU在处理长数字上毫无压力,对于我们这些可怜的在处理长数字上有困难的人类来说,就不用为它烦恼了。这个特征尤其在需要处理大数额金钱、信用卡号码、银行账号以及其它需要长账号的银行和金融领域更有用。尽管在写Java文件里写敏感信息很让人沮丧,我们应该永远不要在编码的时候这么做。但在数字中用下划线让我们的生活比以前变得更加简单了。
Java编码语言对给数值型的字面值加下划线有严格的规定。如上所述,你只能在数字之间用下划线。你不能用把一个数字用下划线开头,或者已下划线结尾。这里有一些其它的不能在数值型字面值上用下划线的地方:
该数值型字面值是字符串类型的时候
这里有一些例子,来表现哪些地方加给数字加下划线有效,哪些地方给数字加下划线无效
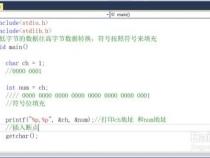
float pi1= 3_.1415F;//无效的;不能在小数点之前有下划线
float pi2= 3._1415F;//无效的;不能在小数点之后有下划线
long socialSecurityNumber1= 999_99_9999_L;//无效的,不能在L下标之前加下划线
int a1= _52;//这是一个下划线开头的标识符,不是个数字
int a3= 52_;//无效的,不能以下划线结尾
int a5= 0_x52;//无效,不能在0x之间有下划线
int a6= 0x_52;//无效的,不能在数字开头有下划线
int a7= 0x5_2;//有效的(16进制数字)
int a8= 0x52_;//无效的,不能以下划线结尾
int a9= 0_52;//有效的(8进制数)
int a10= 05_2;//有效的(8进制数)
int a11= 052_;//无效的,不能以下划线结尾
下面是一些在数字中用下划线的其它示例:
long creditCardNumber= 6684_5678_9012_3456L;//在编码的时候,最好永远不要这么做
long socialSecurityNumber= 333_99_9999L;//在编码的时候,最好永远不要这么做
long maxLong= 0x7fff_ffff_ffff_ffffL;
long bytes= 0b11010010_01101001_10010100_10010010;
使用下划线后,你会发现你的代码比以前可读性更强。顺便说一句,在java中应该一直用L去表示一个长整型数字。尽管用小写的l表示长整型数也是合法的,但他看起来太像1了,所以应该永远都不要用它。告诉我你能不能再 12l和121之间找出差别,我猜能找到的人不多吧。但是在 12L与121之间呢?
总之,要养成在数字中使用下划线的习惯,尤其是对长整型数来说,这样能增加它的可读性。我知道这个功能只是从Java1.7开始才有效,还没有被广泛的使用。但鉴于Java1.8的现状,我期望Java8在Java社区中传播比Java7更加迅速更加广泛。
二、Java下变量大小写驼峰、大小写下划线、大小写连线转换
1、在Java编程中,处理变量的大小写转换是一个常见的需求。无论是为了与数据库字段、属性getter和setter方法进行互换,还是为了遵循特定的命名规范,正确地实现大小写转换至关重要。本文将介绍如何使用Google Guava库来轻松完成这些转换。
2、首先,需要在项目的pom.xml文件中引入Guava依赖包。这一步骤确保了我们能够利用其强大的转换功能。引入过程非常简单,只需添加相应的坐标即可。
3、Guava提供了一个名为CaseFormat的枚举类,它包含五种主要的变量命名规范转换方式。这些枚举分别代表了不同的命名风格,如下所示:
4、CaseFormat.LOWER_HYPHEN:连字符命名规范,用于变量如user-name、user-age。
5、CaseFormat.LOWER_UNDERSCORE:C++风格的下划线命名,形式为lower_underscore。
6、CaseFormat.LOWER_CAMEL:Java风格的小写驼峰命名。
7、CaseFormat.UPPER_CAMEL:Java和C++类名的命名风格,采用大写驼峰形式。
8、CaseFormat.UPPER_UNDERSCORE:Java和C++常量的命名规范,使用下划线分隔大写字母。
9、利用这些枚举,可以实现20种不同的变量命名规范转换方式。接下来,让我们通过几个示例来演示如何使用Guava的CaseFormat类进行变量转换。
10、在实际应用中,这些转换操作可以显著提高代码的可读性和一致性,是编程实践中不可或缺的一部分。深入理解这些转换方法,将使你能够灵活地适应各种项目需求。希望本文提供的信息能够帮助你更好地掌握Java中变量命名规范的转换技巧,祝你编程之路顺利!
三、java 接口返回实体的格式,驼峰和下划线
1、默认接口返回实体的格式是驼峰命名。若需转换为下划线命名,需通过特定策略实现。使用@Jackson注解完成转换。
2、在类上应用@Jackson注解,使用@JsonNaming(PropertyNamingStrategy.SnakeCaseStrategy.class)标记,将驼峰格式转换为下划线格式。同时,为具体字段添加@JsonProperty("page_index")注解,确保字段名遵循预期格式。
3、@JsonNaming(PropertyNamingStrategy.SnakeCaseStrategy.class)
4、@JsonProperty("page_index") private Integer pageIndex;
5、试用上述代码,根据实际需求调整其他策略。
6、采用CamelCase策略,Java对象属性如personId,序列化后属性更改为persionId。
7、选用PascalCase策略,Java对象属性personId,序列化后属性变更为PersonId。
8、应用SnakeCase策略,Java对象属性personId,序列化后属性转换为person_id。
9、采用KebabCase策略,Java对象属性personId,序列化后属性变为person-id。