oracle sql 判断 字段是否是汉字
发布时间:2025-05-13 13:16:38 发布人:远客网络
一、oracle sql 判断 字段是否是汉字
ASCIISTR函数说明:ASCIISTR返回字符的ASCII形式的字符串。非ASCII的字符被转化为\xxxx的形式。使用ASCIISTR函数也是根据非ASCII字符会被转化这个特性来判别中文字符,只要里面包含中文字符,则必定会有\xxx这样的字符。
使用 ASCIISTR(NAME_ONE) LIKE'%\%'就能判别那些有中文的记录。如下所示:
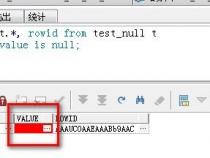
SELECT NAME_ONE FROM TEST WHERE ASCIISTR(NAME_ONE) LIKE'%\%'
CONVERT(inputstring,dest_charset,source_charset)
3、使用函数length和lengthb来判别
使用函数length与lengthb来判别,是基于中文字符占用2~4个字节,而ASCII字符占用一个字节,那么对比LENGTH与LENGTHB就会不一样。这样就能判别字段中是否包含中文字符,但是跟ASCIISTR一样,如果里面的非ASCI字符包含非中文,它一样不能判别。依然有取巧嫌疑。
SELECT NAME_ONE FROM TEST WHERE LENGTH(NAME_ONE)!= LENGTHB(NAME_ONE);
1、SQL语句用大写的;因为Oracle总是先解析SQL语句,把小写的字母转换成大写的再执行。
2、数据表最好起别名;因为便于sql优化器快速分析。
3、尽量不要使用 insert into table value(?,?,?,?,?)格式,要指出具体要赋值的字段。INSERT.....SELECT的效率会有提高。
4、select与from语句之间只定义返回的字段名,除非返回所有的字段,尽量不要使用*。
5、select字段名应按照表的字段物理顺序编写,字段提取要按照“需多少、提多少”的原则,原因是大批量数据的抽取会影响sql缓存的效率。
6、COUNT(*)也是要避免的,因为Count(*)会对全字段做聚集。但一般的观点相反, count(*)比count(1)稍快,当然如果可以通过索引检索,对索引列的计数仍旧是最快的.例如 COUNT(EMPNO)。
7、条件中使用or会引起全表扫描,比较影响查询效率,尽可能少用或不用,实在不行可以用UNION代替。
二、SQL取字段中某一部分特定数值
1、返回字符、binary、text或 image表达式的一部分。有关可与该函数一起使用的有效 Microsoft® SQL Server™数据类型的更多信息,请参见数据类型。
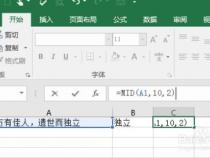
2、SUBSTRING( expression, start, length)
3、是字符串、二进制字符串、text、image、列或包含列的表达式。不要使用包含聚合函数的表达式。
4、是一个整数,指定子串的开始位置。
5、是一个整数,指定子串的长度(要返回的字符数或字节数)。
6、select substring('mgdf13hj44jjjgasetrxzc20/30nj5weyu45f5645gjhkdfjkg',23,5)
三、sql 查询字段中的前几个字
可以使用:substr( string, start_position, [ length ]);string:源字符串;start_position:提取的位置,字符串中第一个位置始终为1;[ length ]:提取的字符数,如果省略,substr将返回整个字符串;
select* from表名wheresubstr([D],1,2)=“10”
语句功能说明:从指定表中查询D字段第1、2个字符为“10的记录”。
语法:substr(string,start,length)
string参数:必选。数据库中需要截取的字段。
正数,从字符串指定位子开始截取;负数,从字符串结尾指定位子开始截取;0,在字符串中第一个位子开始截取。1,同理。(特殊)
length参数:可选。需要截取的长度。缺省,即截取到结束位置。
注意:若必选参数为空,那返回的结果也为空。