用Python 对多维数据进行相关性分析
发布时间:2025-05-13 08:48:29 发布人:远客网络
一、用Python 对多维数据进行相关性分析
1、为了进行多维数据的相关性分析,首先需要导入所需的Python库。在这里,主要使用pandas进行数据读取与处理,以及seaborn和matplotlib进行可视化。本文将使用来自唐白河流域的数据集,包括三个水文站69年洪峰流量和水位数据。数据存储在名为"hy.csv"的文件中。以下将详细展示如何进行相关性分析。
2、在进行具体分析前,我们先加载数据并查看其基本情况。数据集包含69个6维数据点,其中B、C站是A站的上游测站。使用pandas库读取并展示数据的相关性情况。
3、为了直观地分析数据集中特定列之间的相关性,首先关注第1列和第3列,即Q_A和Q_B。接下来,将展示两种不同风格的相关性分析可视化。
4、首先,我们增加拟合线和置信区间来表示这两个变量之间的关系。以下为相应代码。
5、接下来,可以尝试使用蜂窝状的六边形网格来展示点之间的密集程度。以下是对应代码。
6、为了更全面地理解数据集中各维度之间的关系,可以利用seaborn库绘制普通相关关系图,该图包含36个子图,每个子图表示一个维度与其他维度的相关关系。此外,可以将这些关系以特定维度(如Q_A)为基准进行着色,以直观展示数据点的分布。
7、利用seaborn绘制以特定列(如Q_A)为基准的相关关系图的代码如下。
8、同样,可以使用pandas库生成相关关系图,尽管在定制程度和精细度方面略显不足。以下是相应代码。
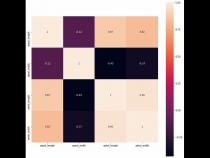
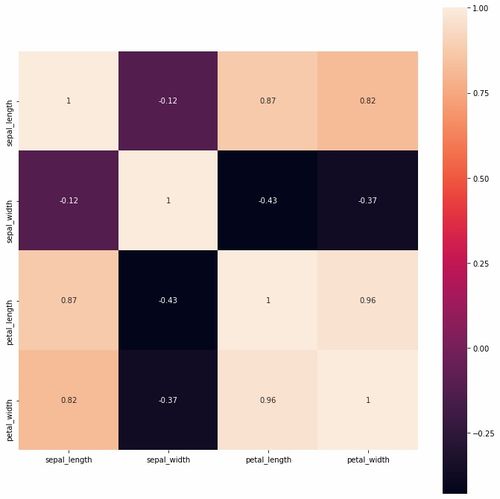
9、最后,为了深入理解数据集的结构,可以利用seaborn库绘制相关关系热力图,并进一步增强其聚类效果,以揭示变量之间的复杂关系。
10、通过上述分析,我们可以有效地对多维数据进行相关性分析,并通过可视化手段直观地理解数据集内部的复杂关系,从而为后续的数据探索与建模提供有力支持。
二、python实现相关性热图(Correlation Heatmap)
1、相关性热图,是一种直观展示数据集矩形矩阵中变量之间相关性的视觉工具。其通过矩阵中的颜色变化,反映变量间相关性程度的高低。seaborn库的heatmap方法,便能实现这一功能。
2、想要生成相关性热图,仅需一行代码:seaborn.heatmap(corr)。这里的corr参数是数据集的相关性矩阵。
3、尽管初始热图可能略显简单,但通过一系列美化步骤,可使其更具观赏性和信息表现力。调整颜色映射、字体大小、添加标题及标签等操作,使热图更具吸引力。
4、此外,相关性热图的美化不仅限于基本调整,还可通过改变颜色条样式、添加网格线等细节,进一步提升视觉效果。个性化设计,让热图更贴合具体应用场景。
5、对于追求高效分析与可视化呈现的用户,seaborn提供的相关性热图生成功能,不仅节省了繁复的Matplotlib配置工作,而且通过直观的热力图形式,快速揭示数据间的关联模式,是数据分析与展示中的强大工具。
三、如何实现两变量之间的相关性分析
1、两变量之间的相关性分析可以通过计算它们的相关系数来实现。常用的相关系数包括:
2、Pearson相关系数:用于衡量两个变量之间的线性相关性,取值范围为-1到1,当值为1时表示完全正相关,为-1时表示完全负相关,为0时表示无相关关系。
3、Spearman等级相关系数:用于衡量两个变量之间的单调相关性,即随着一个变量的增加,另一个变量的趋势是增加或减少。与Pearson相关系数不同的是,Spearman相关系数是通过将变量转换为等级来计算的,因此它也被称为等级相关系数。
4、判定系数:判定系数是通过比较实际观测值和预测值的平均值之间的差异来衡量模型的拟合优度。它的取值范围为0到1,值越接近1表示模型的拟合效果越好。
5、要进行相关性分析,需要先收集两个变量的数据,并将它们输入到统计软件中进行计算。在Excel中,可以使用CORREL函数计算Pearson相关系数;在SPSS、R、Python等统计软件中,也提供了计算相关系数的函数。