ES 查询返回的时间字段指定时区
发布时间:2025-05-13 06:12:18 发布人:远客网络

一、ES 查询返回的时间字段指定时区
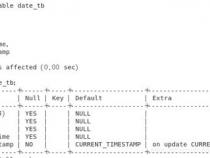
1、Elasticsearch中的`date`和`date_nanos`字段默认存储 UTC时间。若查询时不指定时区,将返回 UTC时间。为获取指定时区时间,可使用 `date_format`格式化并指定时区。如示例:将时间以`yyyy-MM-dd HH:mm:ss`格式并设时区为`Asia/Shanghai`返回。
2、"source":"doc['@timestamp'].date.format('yyyy-MM-dd HH:mm:ss', java.time.ZoneId.of('Asia/Shanghai'))+' CST'"
3、这里使用了 `java.time.ZoneId`工具类指定`Asia/Shanghai`时区,格式化后时间字符串后添加`CST`标识。
4、若文档内时间字段希望查询时返回指定时区时间,字段映射中可添加`timezone`参数,示例如下:
5、"format":"yyyy-MM-dd HH:mm:ss",
6、如此,在查询时,即使不使用`date_format`,结果亦将时间转换为指定时区。
二、es 结果排序
以下是本次实战的环境信息,请确保您的Elasticsearch可以正常运行:
实战用的数据依然是一些汽车销售的记录,在第一章有详细的导入步骤,请参考操作,导入后您的es中的数据如下图:
之前文章中的聚合查询,我们都没有做排序设置,此时es会用每个桶的doc_count字段做降序,下图是个terms桶聚合的示例,可见返回了三个bucket对象,是按照doc_count字段降序排列的:
除了自定义排序,es自身也内置了两种排序参数,可以直接拿来使用:
返回结果如下,已经按照key的大小从大到小排序:
《Elasticsearch权威指南》里指出:_key只在 histogram和 date_histogram内使用,原文如下图红框所示:
但是在实际操作中发现,6.7.1版本中,除了histogram和 date_histogram,terms桶也可以用_key排序,如下图,是按照key的字母降序:
把desc改为asc之后返回如下图,变成了按照key的首字母升序排序:
3.另外《Elasticsearch权威指南》中还提到一种内置排序类型_term,但是《Elasticsearch官方文档》中宣布该类型在6.0之后已经废弃,如下:
也许是"手贱"的缘故,我还是用_term试了下,可以返回结果,但是会建议用_key替代_term,如下图:
常见的metrics有累加和(sum)、最大值(max)、最小值(min)、平均值(avg),这些metrics的特点是处理结果只有一个值,我们可以按照这个结果来排序,例如计算每个汽车品牌的销售额,再按照销售额排序:
下面是聚合结果,可见已按照每个品牌的销售额大小做了降序的排序:
和sum、max这些只有一个结果的metrics不同,extended_stats的结果包含了数量、最大值、最小值、平均值、累加和等多种处理,此时必须要指定用其中的哪一项(否则会返回错误:Invalid aggregation order path [xxxx]. When ordering on a multi-value metrics aggregation a metric name must be specified):
返回结果如下,可见已经按照metrics结果的avg子项做了升序排序:
在聚合查询中,经常对聚合的数据再次做聚合处理,例如统计每个汽车品牌下的每种颜色汽车的销售额,这时候DSL中就有了多层aggs对象的嵌套,这就是嵌套桶(此名称来自《Elasticsearch权威指南》),如下图所示:
嵌套桶的排序情况略为复杂,详情请参考《Elasticsearch聚合的嵌套桶如何排序》;
至此,聚合返回结果排序的实战已经完成了,后面的章节会深入学习es的聚合有关的关键知识点;
三、es 字段类型
|核心类型|字符串类型| string,text,keyword|
|整数类型| integer,long,short,byte|
|浮点类型| double,float,half_float,scaled_float|
|地理类型|地理坐标类型| geo_point|
string类型在ElasticSearch旧版本中使用较多,从ElasticSearch 5.x开始不再支持string,由text和keyword类型替代。
当一个字段是要被全文搜索的,比如Email内容、产品描述,应该使用text类型。设置text类型以后,字段内容会被分析,在生成倒排索引以前,字符串会被分析器分成一个一个词项。text类型的字段不用于排序,很少用于聚合。
keyword类型适用于索引结构化的字段,比如email地址、主机名、状态码和标签。如果字段需要进行过滤(比如查找已发布博客中status属性为published的文章)、排序、聚合。keyword类型的字段只能通过精确值搜索到。
在满足需求的情况下,尽可能选择范围小的数据类型。比如,某个字段的取值最大值不会超过100,那么选择byte类型即可。迄今为止吉尼斯记录的人类的年龄的最大值为134岁,对于年龄字段,short足矣。字段的长度越短,索引和搜索的效率越高。
对于float、half_float和scaled_float,-0.0和+0.0是不同的值,使用term查询查找-0.0不会匹配+0.0,同样range查询中上边界是-0.0不会匹配+0.0,下边界是+0.0不会匹配-0.0。
其中scaled_float,比如价格只需要精确到分,price为57.34的字段缩放因子为100,存起来就是5734
优先考虑使用带缩放因子的scaled_float浮点类型。
我们人类使用的计时系统是相当复杂的:秒是基本单位, 60秒为1分钟, 60分钟为1小时, 24小时是一天……如果计算机也使用相同的方式来计时,那显然就要用多个变量来分别存放年月日时分秒,不停的进行进位运算,而且还要处理偶尔的闰年和闰秒以及协调不同的时区.基于”追求简单”的设计理念, UNIX在内部采用了一种最简单的计时方式:
日期类型表示格式可以是以下几种:
(1)日期格式的字符串,比如“2018-01-13”或“2018-01-13 12:10:30”
(2)long类型的毫秒数( milliseconds-since-the-epoch,epoch就是指UNIX诞生的UTC时间1970年1月1日0时0分0秒)
(3)integer的秒数(seconds-since-the-epoch)
ElasticSearch内部会将日期数据转换为UTC,并存储为milliseconds-since-the-epoch的long型整数。
逻辑类型(布尔类型)可以接受true/false/”true”/”false”值
(1)先删除已经存在的索引,再创建
二进制字段是指用base64来表示索引中存储的二进制数据,可用来存储二进制形式的数据,例如图像。默认情况下,该类型的字段只存储不索引。二进制类型只支持index_name属性。
在ElasticSearch中,没有专门的数组(Array)数据类型,但是,在默认情况下,任意一个字段都可以包含0或多个值,这意味着每个字段默认都是数组类型,只不过,数组类型的各个元素值的数据类型必须相同。在ElasticSearch中,数组是开箱即用的(out of box),不需要进行任何配置,就可以直接使用。
在同一个数组中,数组元素的数据类型是相同的,ElasticSearch不支持元素为多个数据类型:[ 10,“some string” ],常用的数组类型是:
(1)字符数组: [“one”,“two” ]
(2)整数数组: productid:[ 1, 2 ]
(3)对象(文档)数组:“user”:[{“name”:“Mary”,“age”: 12},{“name”:“John”,“age”: 10}],ElasticSearch内部把对象数组展开为{“user.name”: [“Mary”,“John”],“user.age”: [12,10]}
JSON天生具有层级关系,文档会包含嵌套的对象
上面文档整体是一个JSON,JSON中包含一个employee,employee又包含一个fullname。
ip类型的字段用于存储IPv4或者IPv6的地址