Python知识精解:isupper()方法和islower()方法
发布时间:2025-05-13 05:52:46 发布人:远客网络
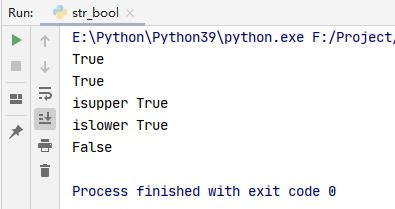
一、Python知识精解:isupper()方法和islower()方法
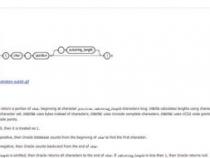
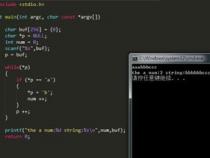
1、isupper()方法用于检查字符串中所有字母是否为大写。如果字符串包含至少一个区分大小写的字符且所有字符都为大写,则返回 True,否则返回 False。
2、islower()方法则检查字符串是否由小写字母组成。如果字符串包含至少一个区分大小写的字符且所有字符都为小写,则返回 True,否则返回 False。
3、这两个方法常用于字符串处理时判断字符大小写状态,有助于实现更精确的文本分析和处理逻辑。
二、Python处理字符串必备方法
字符串是Python中基本的数据类型,几乎在每个Python程序中都会使用到它。
slicing切片,按照一定条件从列表或者元组中取出部分元素(比如特定范围、索引、分割值)
strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
在使用strip()方法时,默认去除空格或换行符,所以#号并没有去除。
可以给strip()方法添加指定字符,如下所示。
此外当指定内容不在头尾处时,并不会被去除。
第一个\n前有个空格,所以只会去取尾部的换行符。
最后strip()方法的参数是剥离其值的所有组合,这个可以看下面这个案例。
最外层的首字符和尾字符参数值将从字符串中剥离。字符从前端移除,直到到达一个不包含在字符集中的字符串字符为止。
移除字符串左侧指定的字符(默认为空格或换行符)或字符序列。
同样的,可以移除左侧所有包含在字符集中的字符串。
移除字符串右侧指定的字符(默认为空格或换行符)或字符序列。
和strip()相比,并不会把字符集中的字符串进行逐个匹配。
把字符串中的内容替换成指定的内容。
re是正则的表达式,sub是substitute表示替换。
和replace()做对比,使用re.sub()进行替换操作,确实更高级点。
对字符串做分隔处理,最终的结果是一个列表。
当不指定分隔符时,默认按空格分隔。
此外,还可以指定字符串的分隔次数。
string.join(seq)。以string作为分隔符,将seq中所有的元素(的字符串表示)合并为一个新的字符串。
将字符串中的字母,全部转换为大写。
将字符串中的字母,全部转换为小写。
将字符串中的首个字母转换为大写。
判断字符串中的所有字母是否都为小写,是则返回True,否则返回False。
判断字符串中的所有字母是否都为大写,是则返回True,否则返回False。
如果字符串至少有一个字符并且所有字符都是字母,则返回 True,否则返回 False。
如果字符串中只包含数字字符,则返回 True,否则返回 False。
如果字符串中至少有一个字符并且所有字符都是字母或数字,则返回True,否则返回 False。
返回指定内容在字符串中出现的次数。
检测指定内容是否包含在字符串中,如果是返回开始的索引值,否则返回-1。
类似于find()函数,返回字符串最后一次出现的位置,如果没有匹配项则返回-1。
检查字符串是否是以指定内容开头,是则返回 True,否则返回 False。
检查字符串是否是以指定内容结束,是则返回 True,否则返回 False。
string.partition(str),有点像find()和split()的结合体。
从str出现的第一个位置起,把字符串string分成一个3元素的元组(string_pre_str,str,string_post_str),如果string中不包含str则 string_pre_str==string。
返回一个原字符串居中,并使用空格填充至长度width的新字符串。
返回一个原字符串左对齐,并使用空格填充至长度width的新字符串。
返回一个原字符串右对齐,并使用空格填充至长度width的新字符串。
f-string是格式化字符串的新语法。
与其他格式化方式相比,它们不仅更易读,更简洁,不易出错,而且速度更快!
返回长度为width的字符串,原字符串string右对齐,前面填充0。
参考文献:
三、python中有哪些基本数据类型
python的基本数据类型有哪些?下面一一给大家介绍:
当然对于数字,Python的数字类型有int整型、long长整型、float浮点数、complex复数、以及布尔值(0和1),这里只针对int整型进行介绍学习。
在Python2中,整数的大小是有限制的,即当数字超过一定的范围不再是int类型,而是long长整型,而在Python3中,无论整数的大小长度为多少,统称为整型int。
int-->将字符串数据类型转为int类型,注:字符串内的内容必须是数字
bit_length()-->将数字转换为二进制,并且返回最少位二进制的位数
对于布尔值,只有两种结果即True和False,其分别对应与二进制中的0和1。而对于真即True的值太多了,我们只需要了解假即Flase的值有哪些---》None、空(即 [ ]/()/""/{})、0;
关于字符串是Python中最常用的数据类型,其用途也很多,我们可以使用单引号‘’或者双引号“”来创建字符串。
字符串是不可修改的。所有关于字符我们可以从索引、切片、长度、遍历、删除、分割、清除空白、大小写转换、判断以什么开头等方面对字符串进行介绍。
index()与find()的不同之处在于:若索引的该字符或者序列不在字符串内,对于index--》ValueError: substring not found,而对于find-->返回-1。
注:len()方法-->同样可以用于其他数据类型,例如查看列表、元组以及字典中元素的多少。
判断字符串内容--> isalnum()、isalpha()、isdigit()
大小写转换--> capitalize()、lower()、upper()、title()、casefold()
判断以什么开头结尾--> startswith()、endswith()
格式化输出-->format()、format_map()
分割--> split()、partition()
替换-->makestran、translate
列表是由一系列特定元素顺序排列的元素组成的,它的元素可以是任何数据类型即数字、字符串、列表、元组、字典、布尔值等等,同时其元素也是可修改的。
names= ['little-five","James","Alex"]2#或者3 names= list(['little-five","James","Alex"])
注:扩展extend与追加append的区别:-->前者为添加将元素作为一个整体添加,后者为将数据类型的元素分解添加至列表内。例:
remove()-->移除、del-->删除
sorted()-->排序,默认正序,加入reverse=True,则表示倒序
元组即为不可修改的列表。其于特性跟list相似。其使用圆括号而不是方括号来标识。
#元组name=("little-five","xiaowu")print(name[0])
字典为一系列的键-值对,每个键值对用逗号隔开,每个键都与一个值相对应,可以通过使用键来访问对应的值。无序的。
键的定义必须是不可变的,即可以是数字、字符串也可以是元组,还有布尔值等。
而值的定义可以是任意数据类型。
关于集合set的定义:在我看来集合就像一个篮子,你可以往里面存东西也可往里面取东西,但是这些东西又是无序的,你很难指定单独去取某一样东西;同时它又可以通过一定的方法筛选去获得你需要的那部分东西。故集合可以创建、增、删、关系运算。
3、每个元素必须为不可变类型即(hashable类型,可作为字典的key)。
关系运算:交集&、并集|、差集-、交差补集 ^、 issubset、isupperset
判断两个集合的关系是否为子集、父集--> issubset、isupperset