Python 数据处理(二十九)—— MultiIndex 高级索引操作
发布时间:2025-05-13 03:31:59 发布人:远客网络
一、Python 数据处理(二十九)—— MultiIndex 高级索引操作
1、多级索引(MultiIndex)在高级索引操作中展现出了强大的灵活性,它允许用户以层次化的方式组织数据,从而实现更精细的数据筛选和分析。在与.loc集成使用时,由于多级索引键通常采用元组形式,操作可能显得稍显复杂。
2、例如,直接使用 df.loc['bar','two']可能会导致歧义,因为它可能被理解为在不同轴上的索引。为了明确地访问某一列,需要使用元组形式的索引,如 df.loc[('bar',),'two']。这表明,虽然在某些情况下可以仅指定一个标签,但在获取某一列的所有元素时,必须提供一个元组。
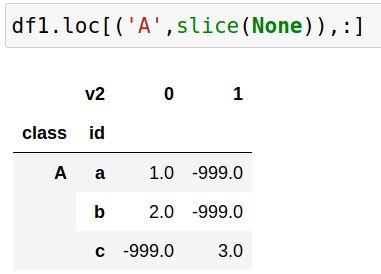
3、多级索引同样支持切片操作。通过提供一个包含多层级切片的元组,可以选取特定范围的值。这种切片方式与传统切片略有不同:列表用于指定多个键,而元组则表示跨多个层级的切片。例如,df.loc[('bar','three'):('foo','four')]可以选取从('bar','three')到('foo','four')的所有元素。
4、在使用.loc时,同时指定索引和标签是非常推荐的,以避免解析错误。例如,df.loc[('bar','three'),'column']相比于 df.loc['bar','three','column'],后者可能会被错误解析为两个轴,而不是一个多级索引。
5、使用切片、列表和标签进行MultiIndex切片,可以实现复杂的选择。通过使用pandas.IndexSlice,可以简化使用切片符号的语法。这种方法在多个轴上进行选择时特别有用。
6、多级索引也支持使用布尔索引器进行选择。同时,可以使用axis参数在特定轴上传递切片,或者使用xs()方法选择特定级别的数据。xs()方法还允许提供多个键进行选择,并允许保留所选择的级别通过传递drop_level参数。
7、在使用pandas对象的reindex()和align()方法时,可以使用level参数在特定级别上广播值,从而实现数据的高级重建和对齐。此外,swaplevel()方法和reorder_levels()方法可以轻松地切换或重新排列层级顺序。
8、多级索引的管理和重命名提供了灵活性。rename()方法可用于重命名标签或列名,rename_axis()方法用于重命名Index或MultiIndex的名称。使用reset_index()可以将MultiIndex移动到列,同时还可以更改DataFrame列索引的名称。rename和rename_axis方法支持使用字典、Series或映射函数进行标签映射。在使用Index对象而非DataFrame时,Index.set_names()可以用来更改名称,而直接使用level设置层级名称通常无效。
二、Python+Pandas入门2——导出csv
1、path_or_buf=None: string or file handle, default None
File path or object, if None is provided the result is returned as a string.
路径或对象,如果没有提供,结果将返回为字符串。
2、sep: character, default‘,’
Field delimiter for the output file.
输出文件的字段分隔符。
3、na_rep: string, default‘’
Missing data representation
字符串,默认为‘’
浮点数格式字符串
4、float_format: string, default None
Format string for floating point numbers
字符串,默认为 None
浮点数格式字符串
5、columns: sequence, optional Columns to write
顺序,可选列写入
6、header: boolean or list of string, default True
Write out the column names. If a list of strings is given it is assumed to be aliases for the column names
字符串或布尔列表,默认为true
写出列名。如果给定字符串列表,则假定为列名的别名。
7、index: boolean, default True
Write row names(index)
布尔值,默认为Ture
写入行名称(索引)
8、index_label: string or sequence, or False, default None
*Column label for index column(s) if desired. If None is given, and header and index are True, then the index names are used. A sequence should be given if the DataFrame uses MultiIndex. If False do not print fields for index names. Use index_label=False for easier importing in R
字符串或序列,或False,默认为None
如果需要,可以使用索引列的列标签。如果没有给出,且标题和索引为True,则使用索引名称。如果数据文件使用多索引,则应该使用这个序列。如果值为False,不打印索引字段。在R中使用 index_label=False更容易导入索引.
9、encoding: string, optional
编码:字符串,可选
表示在输出文件中使用的编码的字符串,Python 2上默认为“ASCII”和Python 3上默认为“UTF-8”。
10、compression: string, optional
表示在输出文件中使用的压缩的字符串,允许值为“gzip”、“bz2”、“xz”,仅在第一个参数是文件名时使用。
11、line_terminator: string, default‘\n’
字符串,默认为‘\n’
在输出文件中使用的换行字符或字符序列
12、quoting: optional constant from csv module
*CSV模块的可选常量
输出是否用引号,默认参数值为0,表示不加双引号,参数值为1,则每个字段都会加上引号,数值也会被当作字符串看待
13、quotechar: string(length 1), default‘”’
*字符串(长度1),默认"
当quoting=1可以指定引号字符为双引号"或单引号'
14、doublequote: boolean, default True
布尔,默认为Ture
控制一个字段内的quotechar
15、escapechar: string(length 1), default None
字符串(长度为1),默认为None
在适当的时候用来转义sep和quotechar的字符
17、tupleize_cols: boolean, default False
布尔值,默认为False
从版本0.21.0中删除:此参数将被删除,并且总是将多索引的每行写入CSV文件中的单独行
(如果值为false)将多索引列作为元组列表(如果TRUE)或以新的、扩展的格式写入,其中每个多索引列是CSV中的一行。
18、date_format: string, default None
字符串,默认为None
字符串对象转换为日期时间对象
19、decimal: string, default‘.’
字符串,默认’。’
字符识别为小数点分隔符。例如。欧洲数据使用’,’
模式:值为‘str’,字符串
Python写模式,默认“w”
三、python读入csv最多多少行(2023年最新解答)
导读:很多朋友问到关于python读入csv最多多少行的相关问题,本文首席CTO笔记就来为大家做个详细解答,供大家参考,希望对大家有所帮助!一起来看看吧!
python读取csv文件出来的是一个一个横向数据的列表list,你想要哪列的数据,只需要list[0],list[1],list[2]……这种取出来就OK了,希望能帮助到你!
理论上不管多少行都能够读取,就是时间问题,不像excel只能读一百多万行
CSV文件本质上就是文本文件,只不过每行的数据用逗号分隔。
所以你当成文本文件打开一行一行的读然后拆分就可以了。
with?open(r'd:\temp\demo.csv',?'r')?as?csv_file:
????????data.append(line.strip().split(','))
#?另外Python标准库里有个CSV模块可以用。
with?open(file_path,?'rb')?as?csv_file:
???data?=?list(csv.reader(csv_file))[1:]??#?去掉首行的列名
还有就是可以用Pandas这个库,dataframe有导入csv功能。
python读取CSV文件
读取一个CSV文件
filepath_or_buffer:str,pathlib。str,pathlib.Path,py._path.local.LocalPathoranyobjectwitharead()method(suchasafilehandleorStringIO)
可以是URL,可用URL类型包括:http,ftp,s3和文件。对于多文件正在准备中
本地文件读取实例:://localhost/path/to/table.csv
指定分隔符。如果不指定参数,则会尝试使用逗号分隔。分隔符长于一个字符并且不是‘\s+’,将使用python的语法分析器。并且忽略数据中的逗号。正则表达式例子:'\r\t'
定界符,备选分隔符(如果指定该参数,则sep参数失效)
delim_whitespace:boolean,defaultFalse.
指定空格(例如’‘或者’‘)是否作为分隔符使用,等效于设定sep='\s+'。如果这个参数设定为Ture那么delimiter参数失效。
header:intorlistofints,default‘infer’
指定行数用来作为列名,数据开始行数。如果文件中没有列名,则默认为0,否则设置为None。如果明确设定header=0就会替换掉原来存在列名。header参数可以是一个list例如:[0,1,3],这个list表示将文件中的这些行作为列标题(意味着每一列有多个标题),介于中间的行将被忽略掉。
注意:如果skip_blank_lines=True那么header参数忽略注释行和空行,所以header=0表示第一行数据而不是文件的第一行。
**names**:array-like,defaultNone
用于结果的列名列表,如果数据文件中没有列标题行,就需要执行header=None。默认列表中不能出现重复,除非设定参数mangle_dupe_cols=True。
index_col:intorsequenceorFalse,defaultNone
用作行索引的列编号或者列名,如果给定一个序列则有多个行索引。
如果文件不规则,行尾有分隔符,则可以设定index_col=False来是的pandas不适用第一列作为行索引。
usecols:array-like,defaultNone
返回一个数据子集,该列表中的值必须可以对应到文件中的位置(数字可以对应到指定的列)或者是字符传为文件中的列名。例如:usecols有效参数可能是[0,1,2]或者是[‘foo’,‘bar’,‘baz’]。使用这个参数可以加快加载速度并降低内存消耗。
as_recarray:boolean,defaultFalse
不赞成使用:该参数会在未来版本移除。请使用pd.read_csv(...).to_records()替代。
返回一个Numpy的recarray来替代DataFrame。如果该参数设定为True。将会优先squeeze参数使用。并且行索引将不再可用,索引列也将被忽略。
**squeeze**:boolean,defaultFalse
如果文件值包含一列,则返回一个Series
在没有列标题时,给列添加前缀。例如:添加‘X’成为X0,X1,...
**mangle_dupe_cols**:boolean,defaultTrue
重复的列,将‘X’...’X’表示为‘X.0’...’X.N’。如果设定为false则会将所有重名列覆盖。
dtype:Typenameordictofcolumn-type,defaultNone
每列数据的数据类型。例如{‘a’:np.float64,‘b’:np.int32}
**engine**:{‘c’,‘python’},optional
Parserenginetouse.TheCengineisfasterwhilethepythonengineiscurrentlymorefeature-complete.
使用的分析引擎。可以选择C或者是python。C引擎快但是Python引擎功能更加完备。
列转换函数的字典。key可以是列名或者列的序号。
**skipinitialspace**:boolean,defaultFalse
忽略分隔符后的空白(默认为False,即不忽略).
skiprows:list-likeorinteger,defaultNone
需要忽略的行数(从文件开始处算起),或需要跳过的行号列表(从0开始)。
从文件尾部开始忽略。(c引擎不支持)
不推荐使用:建议使用skipfooter,功能一样。
需要读取的行数(从文件头开始算起)。
na_values:scalar,str,list-like,ordict,defaultNone
一组用于替换NA/NaN的值。如果传参,需要制定特定列的空值。默认为‘1.#IND’,‘1.#QNAN’,‘N/A’,‘NA’,‘NULL’,‘NaN’,‘nan’`.
**keep_default_na**:bool,defaultTrue
如果指定na_values参数,并且keep_default_na=False,那么默认的NaN将被覆盖,否则添加。
**na_filter**:boolean,defaultTrue
是否检查丢失值(空字符串或者是空值)。对于大文件来说数据集中没有空值,设定na_filter=False可以提升读取速度。
是否打印各种解析器的输出信息,例如:“非数值列中缺失值的数量”等。
skip_blank_lines:boolean,defaultTrue
如果为True,则跳过空行;否则记为NaN。
**parse_dates**:booleanorlistofintsornamesorlistoflistsordict,defaultFalse
infer_datetime_format:boolean,defaultFalse
如果设定为True并且parse_dates可用,那么pandas将尝试转换为日期类型,如果可以转换,转换方法并解析。在某些情况下会快5~10倍。
**keep_date_col**:boolean,defaultFalse
如果连接多列解析日期,则保持参与连接的列。默认为False。
date_parser:function,defaultNone
用于解析日期的函数,默认使用dateutil.parser.parser来做转换。Pandas尝试使用三种不同的方式解析,如果遇到问题则使用下一种方式。
1.使用一个或者多个arrays(由parse_dates指定)作为参数;
2.连接指定多列字符串作为一个列作为参数;
3.每行调用一次date_parser函数来解析一个或者多个字符串(由parse_dates指定)作为参数。
**dayfirst**:boolean,defaultFalse
**iterator**:boolean,defaultFalse
返回一个TextFileReader对象,以便逐块处理文件。
文件块的大小,SeeIOToolsdocsformoreinformationoniteratorandchunksize.
compression:{‘infer’,‘gzip’,‘bz2’,‘zip’,‘xz’,None},default‘infer’
直接使用磁盘上的压缩文件。如果使用infer参数,则使用gzip,bz2,zip或者解压文件名中以‘.gz’,‘.bz2’,‘.zip’,or‘xz’这些为后缀的文件,否则不解压。如果使用zip,那么ZIP包中国必须只包含一个文件。设置为None则不解压。
新版本0.18.1版本支持zip和xz解压
千分位分割符,如“,”或者“."
字符中的小数点(例如:欧洲数据使用’,‘).
float_precision:string,defaultNone
SpecifieswhichconvertertheCengineshoulduseforfloating-pointvalues.TheoptionsareNonefortheordinaryconverter,highforthehigh-precisionconverter,andround_tripfortheround-tripconverter.
**lineterminator**:str(length1),defaultNone
**quotechar**:str(length1),optional
引号,用作标识开始和解释的字符,引号内的分割符将被忽略。
quoting:intorcsv.QUOTE_*instance,default0
控制csv中的引号常量。可选QUOTE_MINIMAL(0),QUOTE_ALL(1),QUOTE_NONNUMERIC(2)orQUOTE_NONE(3)
doublequote:boolean,defaultTrue
双引号,当单引号已经被定义,并且quoting参数不是QUOTE_NONE的时候,使用双引号表示引号内的元素作为一个元素使用。
escapechar:str(length1),defaultNone
当quoting为QUOTE_NONE时,指定一个字符使的不受分隔符限值。
标识着多余的行不被解析。如果该字符出现在行首,这一行将被全部忽略。这个参数只能是一个字符,空行(就像skip_blank_lines=True)注释行被header和skiprows忽略一样。例如如果指定comment='#'解析‘#empty\na,b,c\n1,2,3’以header=0那么返回结果将是以’a,b,c'作为header。
指定字符集类型,通常指定为'utf-8'.ListofPythonstandardencodings
dialect:strorcsv.Dialectinstance,defaultNone
如果没有指定特定的语言,如果sep大于一个字符则忽略。具体查看csv.Dialect文档
tupleize_cols:boolean,defaultFalse
Leavealistoftuplesoncolumnsasis(defaultistoconverttoaMultiIndexonthecolumns)
error_bad_lines:boolean,defaultTrue
如果一行包含太多的列,那么默认不会返回DataFrame,如果设置成false,那么会将改行剔除(只能在C解析器下使用)。
warn_bad_lines:boolean,defaultTrue
如果error_bad_lines=False,并且warn_bad_lines=True那么所有的“badlines”将会被输出(只能在C解析器下使用)。
**low_memory**:boolean,defaultTrue
分块加载到内存,再低内存消耗中解析。但是可能出现类型混淆。确保类型不被混淆需要设置为False。或者使用dtype参数指定类型。注意使用chunksize或者iterator参数分块读入会将整个文件读入到一个Dataframe,而忽略类型(只能在C解析器中有效)
**buffer_lines**:int,defaultNone
不推荐使用,这个参数将会在未来版本移除,因为他的值在解析器中不推荐使用
compact_ints:boolean,defaultFalse
不推荐使用,这个参数将会在未来版本移除
如果设置compact_ints=True,那么任何有整数类型构成的列将被按照最小的整数类型存储,是否有符号将取决于use_unsigned参数
use_unsigned:boolean,defaultFalse
不推荐使用:这个参数将会在未来版本移除
如果整数列被压缩(i.e.compact_ints=True),指定被压缩的列是有符号还是无符号的。
memory_map:boolean,defaultFalse
如果使用的文件在内存内,那么直接map文件使用。使用这种方式可以避免文件再次进行IO操作。
df=pd.read_csv("你的文件路径")
结语:以上就是首席CTO笔记为大家介绍的关于python读入csv最多多少行的全部内容了,希望对大家有所帮助,如果你还想了解更多这方面的信息,记得收藏关注本站。