hive学习笔记:substr()——字符串截取
发布时间:2025-05-12 18:14:44 发布人:远客网络
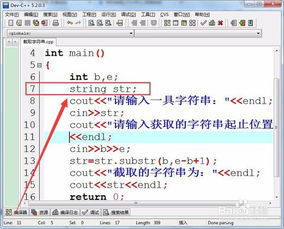
一、hive学习笔记:substr()——字符串截取
1、Hive字符串截取函数substr()详解
2、Hive中,substr()函数是一项强大的工具,用于从输入字符串中提取特定的部分。例如,你可以利用它从日期字符串中精准地获取年份或月份信息,这对于数据分析时处理日期格式尤其有用。
3、尽管substr()是首选,但hive还提供了substring()函数,其基本用法与substr类似。不过,关于两者之间可能存在的细微差别,在本文中暂不作深入探讨。
4、substr()的具体用法是:它接受两个参数,第一个是目标字符串,第二个是开始位置,第三个是可选的长度参数,表示要截取的字符数。例如,如果你想从"2022-06-15"中获取年份,可以使用substr("2022-06-15", 1, 4)。
5、接下来,我们来看一个substring()的简单示例,它与substr函数的结果是一致的,但具体使用时可以根据个人偏好选择。
二、关于在Hive中将特定字符分隔的字符串拆分成多行的应用
Subject:关于在 Hive中将特定字符分隔的字符串拆分成多行的应用
Keys: lateral view、 split、 explode、 HQL、 Hive、数据拆分
有问卷p1,p2,p3,每个问卷含有问题q1,q2,q3...,每个问题对应答案a11,a21,a31,问题与答案之间,用':'分隔,每个问题之间以','分隔.例如:q1:a11,q2:a21,q3:a31:a32
将问题与答案拆分成独立的列,如:
使用lateral View结合Explode实现数据拆分。
lateral view用于和split、explode等UDTF一起使用的,能将一行数据拆分成多行数据,在此基础上可以对拆分的数据进行聚合,lateral view首先为原始表的每行调用UDTF,UDTF会把一行拆分成一行或者多行,lateral view在把结果组合,产生一个支持别名表的虚拟表。
lateral View: LATERAL VIEW udtf(expression) tableAlias AS columnAlias(',' columnAlias)*
from Clause: FROM baseTable(lateralView)*
2). Lateral View用于UDTF(user-defined table generating functions)中将行转成列,例如explode().
3).目前Lateral View不支持有上而下的优化。如果使用Where子句,查询可能将不被编译。解决方法见:此时,在查询之前执行et hive.optimize.ppd=false;
drop table temp_bigdata.test_p1;
create table temp_bigdata.test_p1 as
select'p1' as p,'q1:a11,q2:a21,q3:a31:a32' as qa from default.dual union all
select'p2' as p,'q1:a11,q2:a21:a22,q3:a31:a32' as qa from default.dual union all
select'p3' as p,'q1:a11,q2:a21,q3:' as qa from default.dual;
select* from temp_bigdata.test_p1;
p3 q1:a11,q2:a21,q3
p2 q1:a11,q2:a21:a22,q3:a31:a32
p1 q1:a11,q2:a21,q3:a31:a32
select explode(split(qa,',')) as qa1 from temp_bigdata.test_p1;
2.4开始处理,先将问题拆分成独立行
drop table temp_bigdata.test_p1_adid;
create table temp_bigdata.test_p1_adid as
select row_number() over(order by p,adid) rid,p, adid
from temp_bigdata.test_p1 LATERAL VIEW explode(split(qa,',')) adtable AS adid;
select* from temp_bigdata.test_p1_adid;
rid p adid
1 p1 q1:a11
2 p1 q2:a21
3 p1 q3:a31:a32
4 p2 q1:a11
5 p2 q2:a21:a22
6 p2 q3:a31:a32
7 p3 q1:a11
8 p3 q2:a21
9 p3 q3:
2.5再将每个问题中的问题及答案拆分成多行
create table temp_bigdata.test_p1_adid2 as
p,
adid,--拆分后的问题和答案
split(adid,':')[0] as q, --取出问题
adid2 --拆分答案为行
from temp_bigdata.test_p1_adid
LATERAL VIEW explode(split(adid,':')) adttable2 as adid2;
select* from temp_bigdata.test_p1_adid2;
rid p adid q adid2
1 p1 q1:a11 q1 q1
1 p1 q1:a11 q1 a11
2 p1 q2:a21 q2 q2
2 p1 q2:a21 q2 a21
3 p1 q3:a31:a32 q3 q3
3 p1 q3:a31:a32 q3 a31
3 p1 q3:a31:a32 q3 a32
4 p2 q1:a11 q1 q1
4 p2 q1:a11 q1 a11
5 p2 q2:a21:a22 q2 q2
5 p2 q2:a21:a22 q2 a21
5 p2 q2:a21:a22 q2 a22
6 p2 q3:a31:a32 q3 q3
6 p2 q3:a31:a32 q3 a31
6 p2 q3:a31:a32 q3 a32
7 p3 q1:a11 q1 q1
7 p3 q1:a11 q1 a11
8 p3 q2:a21 q2 q2
8 p3 q2:a21 q2 a21
9 p3 q3: q3 q3
9 p3 q3: q3
2.6取出结果,将多余行过滤,及问题列=拆分后的答案列
select* from temp_bigdata.test_p1_adid2 where q<>adid2 order by rid,adid;
rid p adid q adid2
1 p1 q1:a11 q1 a11
2 p1 q2:a21 q2 a21
3 p1 q3:a31:a32 q3 a32
3 p1 q3:a31:a32 q3 a31
4 p2 q1:a11 q1 a11
5 p2 q2:a21:a22 q2 a22
5 p2 q2:a21:a22 q2 a21
6 p2 q3:a31:a32 q3 a32
6 p2 q3:a31:a32 q3 a31
7 p3 q1:a11 q1 a11
8 p3 q2:a21 q2 a21
9 p3 q3: q3 Null
OK,得到了想要的结果,说明成功了,可以看到最后一条记录,也能正确的被处理。
1、写法有点怪,一定不要写错;
2、不要忘记起别名,要不select没列可写。
三、hive分隔符支持多个字符吗
PIG中输入输出分隔符默认是制表符\t,而到了hive中,默认变成了八进制的\001,
001 1 01 SOH(start of heading)
官方的解释说是尽量不和文中的字符重复,因此选用了 crtrl- A,单个的字符可以通过
row format delimited fields terminated by'#';指定,PIG的单个分隔符的也可以通过 PigStorage指定,
但是多个字符做分隔符呢?PIG是直接报错,而HIVE只认第一个字符,而无视后面的多个字符。
PIG可以自定义加载函数(load function):继承LoadFunc,重写几个方法就ok了,
而在hive中,自定义多分隔符(Multi-character delimiter strings),有2种方法可以实现:
RegexSerDe是hive自带的一种序列化/反序列化的方式,主要用来处理正则表达式。
01 add jar/home/june/hadoop/hive-0.8.1-bin/lib/hive_contrib.jar;
07 SERDE'org.apache.hadoop.hive.contrib.serde2.RegexSerDe'
09('input.regex'='([^,]*),,,,([^,]*),,,,([^,]*)',
10'output.format.string'='%1$s%2$s%3$s')
17 load data local inpath'b.txt' overwrite into table b;
2、重写相应的 InputFormat和OutputFormat方法:
原理很简单:hive的内部分隔符是“\001”,只要把分隔符替换成“\001”即可。
3、顺便提下如何定制hive中NULL的输出,默认在存储时被转义输出为\N,
如果我们需要修改成自定义的,例如为空,同样我们也要利用正则序列化:
01 hive> CREATE TABLE sunwg02(id int,name STRING)
02 ROW FORMAT SERDE'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
04'field.delim'='\t',
05'escape.delim'='\\',
06'serialization.null.format'='
11 hive> insert overwrite table sunwg02 select* from sunwg00;
12 Loading data to table sunwg02
18 [hjl@sunwg src]$ hadoop fs-cat/hjl/sunwg02/attempt_201105020924_0013_m_000000_0
22 NULL值没有被转写成’\N’