splitlines()方法-将字符串分割成列表
发布时间:2025-05-11 20:28:29 发布人:远客网络

一、1. splitlines()方法-将字符串分割成列表
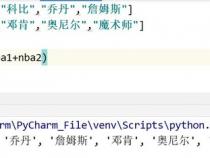
1、splitlines()方法在Python中用于将字符串按照换行符\n、\r、\r\n进行分割,将字符串转换为一个列表。这个30分钟的学习内容涵盖了转义字符的使用和splitlines()方法的基本概念、语法、示例和实际应用。
2、转义字符通过改变字符含义,插入特殊字符或实现特定功能,如换行符\n用于表示新行,回车符\r表示回车。splitlines()方法就是依据这些字符来分割字符串的,返回值为一个列表。
3、在示例中,str_1中不同类型的分隔符处理结果各异,如全是换行符会得到无\n的列表,全是回车符则无\r。使用keepends=True可以保留分割符。实战中,splitlines()常用于处理文本文件,如读取古诗.txt,将其内容按行分割。
4、最后,关于断舍离的表述与本文主题无关,因此未做修改。
二、python里面的代码有多少单词
导读:很多朋友问到关于python里面的代码有多少单词的相关问题,本文首席CTO笔记就来为大家做个详细解答,供大家参考,希望对大家有所帮助!一起来看看吧!
来输入N*10行,每一行有一个单词,一个整数(表示评分),由空格隔开
42个单词是学习Python必须背会的单词,也是代码中常见的单词,很多人声称自己精通Python,然后自己却写不出Pythonic的代码,对很多常用的包不是很了解。
在Python中,有一些字符串具有某些特定功能,如import、class等。我们在选择变量名时,应注意避开这些保留字符。
楼上的程序存在诸多问题,如没有处理标点,文件读取方法错误等。
请问楼主要区分大小写吗?如果区分的话,就按照下面的来:
defget_word_frequencies(file_name):
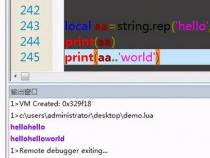
txt=open(filename,'r').read().splitlines()
#下面这句替换了除了'-'外的所有标点,因为'-'可能存在于单词中。
txt=re.sub(r'[^\u4e00-\u94a5\w\d\-]','',txt)
#如果不区分大小写,那就一律按照小写处理,下面那句改为dic.setdefault(word.lower(),0)
get_word_frequencies('test.txt')
说明:上图红框处的result可不写,只是为了看一下分隔结果是否正确.
python常用单词
一、交互式环境与print输出
3、capitalize:用大写字母写或印刷
returnsandlen(s。strip())0
#如果直接单写s。strip()那么s如果是None,会报错,因为None没有strip方法。
#如果s是None,那么Noneand任何值都是False,直接返回false
#如果s非None,那么判定s。trip()是否为空。
这样子filter能过滤到None,"",""这样的值。
分成两部分看。第一部分是对长度进行序列。相当于就是range(5)他的结果就是。01234。第二部分就是具体的排序规则。排序规则是用nums的值进行排序,reverse没申明就是默认升序。就是用nums(0到4)的值进行排序,根据这个结果返回的一个range(5)的数组。
根据PEP的规定,必须使用4个空格来表示每级缩进。使用Tab字符和其它数目的空格虽然都可以编译通过,但不符合编码规范。支持Tab字符和其它数目的空格仅仅是为兼容很旧的的Python程序和某些有问题的编辑程序。
Python的函数支持递归、默认参数值、可变参数,但不支持函数重载。为了增强代码的可读性,可以在函数后书写“文档字符串”(DocumentationStrings,或者简称docstrings),用于解释函数的作用、参数的类型与意义、返回值类型与取值范围等。可以使用内置函数help()打印出函数的使用帮助。
使用比较基本的方法写的参考代码:
#wd来存储单词集合,可能有几个,比如2个单词,都出现30次
#max用来存储单词出现的最多的次数
print?u'有%s个单词,出现频率最高:'%len(wd)
A?good?beginning?makes?a?good?ending!!!
结语:以上就是首席CTO笔记为大家整理的关于python里面的代码有多少单词的相关内容解答汇总了,希望对您有所帮助!如果解决了您的问题欢迎分享给更多关注此问题的朋友喔~
三、python统计文本有多少个单词(2023年最新分享)
导读:今天首席CTO笔记来给各位分享关于python统计文本有多少个单词的相关内容,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
1、首先,定义一个变量,保存要统计的英文文章。
2、接着,定义两个数组,保存文章中的单词,以及各单词的词频。
3、从文章中分割出所有的单词,保存在数组中。
4、然后,计算文章中单词的总数,保存在变量中。
5、用for循环,统计文章中各单词的词频。
6、最后,输出文章中各单词的词频。
7、运行程序,电脑会自动统计输入文章中各单词的词频。
楼上的程序存在诸多问题,如没有处理标点,文件读取方法错误等。
请问楼主要区分大小写吗?如果区分的话,就按照下面的来:
defget_word_frequencies(file_name):
txt=open(filename,'r').read().splitlines()
#下面这句替换了除了'-'外的所有标点,因为'-'可能存在于单词中。
txt=re.sub(r'[^\u4e00-\u94a5\w\d\-]','',txt)
#如果不区分大小写,那就一律按照小写处理,下面那句改为dic.setdefault(word.lower(),0)
get_word_frequencies('test.txt')
用python统计一段文本中单词出现的次数
python有个特别简单的方法就可以实现,直接用str的count方法就可以了,如下
python有个特别简单的方法就可以实现,直接用str的count方法就可以了,如下
使用比较基本的方法写的参考代码:
#wd来存储单词集合,可能有几个,比如2个单词,都出现30次
#max用来存储单词出现的最多的次数
print?u'有%s个单词,出现频率最高:'%len(wd)
A?good?beginning?makes?a?good?ending!!!
如果你是指一串单词,空格隔开的,统计词频,就用列表和字典来。
比如输入的是这样:thisoneokthisonetwothreegoendatend
你好,楼主,可以使用字符串的统计函数来完成。
w='python,我爱python,hellopython。'
print("python出现了%s次"%w.count('python'))
结语:以上就是首席CTO笔记为大家整理的关于python统计文本有多少个单词的全部内容了,感谢您花时间阅读本站内容,希望对您有所帮助,更多关于python统计文本有多少个单词的相关内容别忘了在本站进行查找喔。