python爬虫有什么用
发布时间:2025-05-24 12:49:16 发布人:远客网络
一、python爬虫有什么用
1、Python爬虫是用Python编程语言实现的网络爬虫,主要用于网络数据的抓取和处理,相比于其他语言,Python是一门非常适合开发网络爬虫的编程语言,大量内置包,可以轻松实现网络爬虫功能。
2、Python爬虫可以做的事情很多,如搜索引擎、采集数据、广告过滤等,Python爬虫还可以用于数据分析,在数据的抓取方面可以作用巨大!
二、Python爬虫是什么
为自动提取网页的程序,它为搜索引擎从万维网上下载网页。
网络爬虫为一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。
将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索。
1、由Python标准库提供了系统管理、网络通信、文本处理、数据库接口、图形系统、XML处理等额外的功能。
2、按照网页内容目录层次深浅来爬行页面,处于较浅目录层次的页面首先被爬行。当同一层次中的页面爬行完毕后,爬虫再深入下一层继续爬行。
3、文本处理,包含文本格式化、正则表达式匹配、文本差异计算与合并、Unicode支持,二进制数据处理等功能。
参考资料来源:百度百科-网络爬虫
三、网络爬虫是用来干嘛的
python是一种计算机的编程语言,是这么多计算机编程语言中比较容易学的一种,而且应用也广,这python爬虫是什么意思呢?和IPIDEA全球http去了解一下python爬虫的一些基础知识。
爬虫:是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
即:打开一个网页,有个工具,可以把网页上的内容获取下来,存到你想要的地方,这个工具就是爬虫。
1.网页解析器,将一个网页字符串进行解析,可以按照我们的要求来提取出我们有用的信息,也可以根据DOM树的解析方式来解析。
2.URL管理器:包括待爬取的URL地址和已爬取的URL地址,防止重复抓取URL和循环抓取URL,实现URL管理器主要用三种方式,通过内存、数据库、缓存数据库来实现。
3.网页下载器:通过传入一个URL地址来下载网页,将网页转换成一个字符串,网页下载器有urllib2(Python官方基础模块)包括需要登录、代理、和cookie,requests(第三方包)
4.调度器:相当于一台电脑的CPU,主要负责调度URL管理器、下载器、解析器之间的协调工作。
5.应用程序:就是从网页中提取的有用数据组成的一个应用。
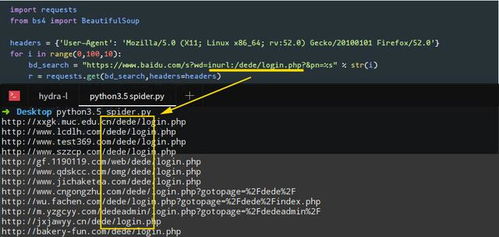
抓取网页有时候需要模拟浏览器的行为,很多网站对于生硬的爬虫抓取都是封杀的。这是我们需要模拟user agent的行为构造合适的请求,比如模拟用户登陆、模拟session/cookie的存储和设置。
抓取的网页通常需要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简洁的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能很多语言和工具都能做,但是用python能够干得最快,最干净。上文介绍了python爬虫的一些基础知识,相信大家对于“python爬虫是什么意思”与“爬虫怎么抓取数据”有一定的的认识了。现在大数据时代,很多学python的时候都是以爬虫入手,学习网络爬虫的人越来越多。通常使用爬虫抓取数据都会遇到IP限制问题,使用高匿代理,可以突破IP限制,帮助爬虫突破网站限制次数。