求教awk两个字符之间截取字符串的方法
发布时间:2025-05-13 17:35:51 发布人:远客网络
一、求教awk两个字符之间截取字符串的方法
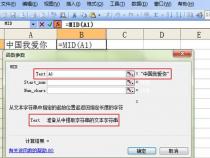
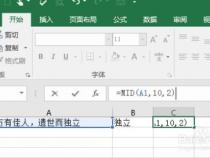
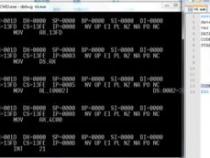
1、在处理字符串时,有时需要截取特定字符之间的内容。假设我们有字符串str="abcdefg",我们想要截取c和f之间的字符串,即得到"de"。这里提供三种方法来实现这个需求。
2、第一种方法是利用awk的split函数。通过将字符串以c和f为分隔符进行分割,并打印分割后的第二个字段,可以得到我们想要的结果。具体命令为:
3、echo"$str"|awk'{split($0,a,"[cf]");printa[2]}'
4、第二种方法则是计算c和f在字符串中的位置,然后利用substr函数来截取目标字符串。具体步骤包括:先找出c和f在字符串中的位置,然后根据位置信息计算出截取的起始位置和长度,最后调用substr函数实现截取。命令如下:
5、echo"$str"|awk'{a=index($0,"c");b=index($0,"f");printsubstr($0,a+1,b-a-1)}'
6、第三种方法是使用sed命令。sed可以利用正则表达式进行文本处理,通过匹配特定模式来实现截取。具体命令如下:
7、echo"$str"|sed-r's/.*c(.*)f.*/\1/'
8、以上三种方法都可以实现从字符串中截取特定字符之间的内容,选择哪种方法可以根据实际需求和个人偏好来决定。
二、如何使用awk按模式筛选文本或字符串
作为 awk命令系列的第三部分,这次我们将看一看如何基于用户定义的特定模式来筛选文本或字符串。
在筛选文本时,有时你可能想根据某个给定的条件或使用一个可被匹配的特定模式,去标记某个文件或数行字符串中的某几行。使用 awk来完成这个任务是非常容易的,这也正是 awk中可能对你有所帮助的几个功能之一。
让我们看一看下面这个例子,比方说你有一个写有你想要购买的食物的购物清单,其名称为 food_prices.list,它所含有的食物名称及相应的价格如下所示:
然后,你想使用一个(*)符号去标记那些单价大于$2的食物,那么你可以通过运行下面的命令来达到此目的:
$ awk'/*\$[2-9]\.[0-9][0-9]*/{ print$1,$2,$3,$4,"*";}/*\$[0-1]\.[0-9][0-9]*/{ print;}' food_prices.list
从上面的输出你可以看到在含有芒果mangoes和菠萝pineapples的那行末尾都已经有了一个(*)标记。假如你检查它们的单价,你可以看到它们的单价的确超过了$2。
在这个例子中,我们已经使用了两个模式:
第一个模式:/*\$[2-9]\.[0-9][0-9]*/将会得到那些含有食物单价大于$2的行,
第二个模式:/*\$[0-1]\.[0-9][0-9]*/将查找那些食物单价小于$2的那些行。
上面的命令具体做了什么呢?这个文件有四个字段,当模式一匹配到含有食物单价大于$2的行时,它便会输出所有的四个字段并在该行末尾加上一个(*)符号来作为标记。
第二个模式只是简单地输出其他含有食物单价小于$2的行,按照它们出现在输入文件 food_prices.list中的样子。
这样你就可以使用模式来筛选出那些价格超过$2的食物项目,尽管上面的输出还有些问题,带有(*)符号的那些行并没有像其他行那样被格式化输出,这使得输出显得不够清晰。
我们在 awk系列的第二部分中也看到了同样的问题,但我们可以使用下面的两种方式来解决:
1、可以像下面这样使用 printf命令,但这样使用又长又无聊:
$ awk'/*\$[2-9]\.[0-9][0-9]*/{ printf"%-10s%-10s%-10s%-10s\n",$1,$2,$3,$4"*";}/*\$[0-1]\.[0-9][0-9]*/{ printf"%-10s%-10s%-10s%-10s\n",$1,$2,$3,$4;}' food_prices.list
使用 Awk和 Printf来筛选和输出项目
2、使用$0字段。Awk使用变量 0来存储整个输入行。对于上面的问题,这种方式非常方便,并且它还简单、快速:
$ awk'/*\$[2-9]\.[0-9][0-9]*/{ print$0"*";}/*\$[0-1]\.[0-9][0-9]*/{ print;}' food_prices.list
使用 Awk和变量来筛选和输出项目
这就是全部内容了,使用 awk命令你便可以通过几种简单的方法去利用模式匹配来筛选文本,帮助你在一个文件中对文本或字符串的某些行做标记。
希望这篇文章对你有所帮助。记得阅读这个系列的下一部分,我们将关注在 awk工具中使用比较运算符。
三、如何使用 awk 和正则表达式过滤文本或文件中的字符串
1、首先我有个文件1,里面是这些字符串(cat 1),但是我想用awk把中间的xyz过滤出来怎么办?
2、-F指定分隔符,这里我用的是扩展正则,意思是以"_."为分隔符,这样把一行字符串分割成了三列,然后我分别打印了第一列,第二列,第三列
3、扩展正则是awk的用法之一,还有简单一些的用法,见下图
4、awk默认使用空格做为分隔符,可以看到,我输出了"a b c d e"每个字母之间都有个空格
5、刚好我可以利用awk默认使用空格作为分隔符这一特点来进行分割过滤
6、这样过滤出来的第一列就是a,第二列就是b......以此类推。
7、如果有复杂的、难处理的可以继续追问,我也很喜欢解决这些问题