Linux如何使用inode删除文件
发布时间:2025-05-12 08:12:46 发布人:远客网络
一、Linux如何使用inode删除文件
文件的inode定义了文件的大小、所有人等文件的特征。每个文件和目录都有自己唯一的inode数字。但是为什么用inode来删除文件,而不是用常用的rm-rf命令呢?原因是,如果你不小心创建了含有特殊字符的文件和目录,比如带有?* ^的文件名,就会很难删除。下面我们就来介绍一下:1)如何找出文件和目录的inode;2)配合find命令,删除特定的inode文件;3)其他有用的删除顽固文件的方法。
用stat或者ls-il。带有-i参数的ls命令,就是指显示文件的inode。
*找到inode后,如何删除这个文件?
find.-inum [inode数字]-exec rm-i{}/;
1)下面我们完整实验一下,创建一个带特殊字符的文件:
342137-rw-r–r– 1 tw tw 0 2008-11-20 08:57/+Xy/+/8
4)342137就是我们要找的inode数字。下面用find命令删除它
$ find.-inum 342137-exec rm-i{}/;
比如,你的系统中有”2008/11/20″这个文件,用rm是删除不了的。Linux不允许你建立这个文件,但是Windows下就可以。所以find配合inode的用处就在这里。
下面介绍一下其他有用的删除技巧:
*可以尝试用文件名加引号的方法删除文件。比如“–help”文件,可以用rm“–help”删除
*也可以用unlink删除文件。unlink。unlink命令调用unlink函数,可以删除一个特定文件
*用mtools删除Windows下创建的非法文件。这种方法在find命令配合inode失效时,最为有用。专门对付autorun.inf病毒创建的文件夹。
也可以xargs配合rm批量删除在不同位置的文件:把待删文件的完整路径都写入一个文本文件,如file.txt内容如下:
然后运行下面的命令删除file.txt中所列的文件
二、Linux文件系统中的inode节点详细介绍
文件储存在硬盘上,硬盘的最小存储单位叫做"扇区"(Sector)。每个扇区储存512字节(相当于0.5KB)。
操作系统读取硬盘的时候,不会一个个扇区地读取,这样效率太低,而是一次性连续读取多个扇区,即一次性读取一个"块"(block)。这种由多个扇区组成的"块",是文件存取的最小单位。"块"的大小,最常见的是4KB,即连续八个 sector组成一个 block。
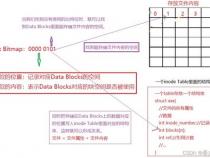
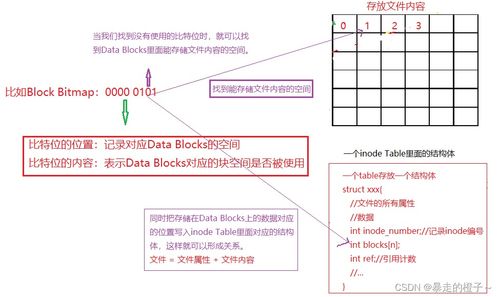
文件数据都储存在"块"中,那么很显然,我们还必须找到一个地方储存文件的元信息,比如文件的创建者、文件的创建日期、文件的大小等等。这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。
inode包含文件的元信息,具体来说有以下内容:
*文件的时间戳,共有三个:ctime指inode上一次变动的时间,mtime指文件内容上一次变动的时间,atime指文件上一次打开的时间。
*链接数,即有多少文件名指向这个inode
*文件数据block的位置
可以用stat命令,查看某个文件的inode信息:
可以用stat命令,查看某个文件的inode信息:
总之,除了文件名以外的所有文件信息,都存在inode之中。至于为什么没有文件名,下文会有详细解释。
inode也会消耗硬盘空间,所以硬盘格式化的时候,操作系统自动将硬盘分成两个区域。一个是数据区,存放文件数据;另一个是inode区(inode table),存放inode所包含的信息。
每个inode节点的大小,一般是128字节或256字节。inode节点的总数,在格式化时就给定,一般是每1KB或每2KB就设置一个inode。假定在一块1GB的硬盘中,每个inode节点的大小为128字节,每1KB就设置一个inode,那么inode table的大小就会达到128MB,占整块硬盘的12.8%。
查看每个硬盘分区的inode总数和已经使用的数量,可以使用df命令。
查看每个inode节点的大小,可以用如下命令:
复制代码代码如下:sudo dumpe2fs-h/dev/hda| grep"Inode size"
由于每个文件都必须有一个inode,因此有可能发生inode已经用光,但是硬盘还未存满的情况。这时,就无法在硬盘上创建新文件。
四、inode号码
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
每个inode都有一个号码,操作系统用inode号码来识别不同的文件。
这里值得重复一遍,Unix/Linux系统内部不使用文件名,而使用inode号码来识别文件。对于系统来说,文件名只是inode号码便于识别的别称或者绰号。表面上,用户通过文件名,打开文件。实际上,系统内部这个过程分成三步:首先,系统找到这个文件名对应的inode号码;其次,通过inode号码,获取inode信息;最后,根据inode信息,找到文件数据所在的block,读出数据。
使用ls-i命令,可以看到文件名对应的inode号码:
Unix/Linux系统中,目录(directory)也是一种文件。打开目录,实际上就是打开目录文件。
目录文件的结构非常简单,就是一系列目录项(dirent)的列表。每个目录项,由两部分组成:所包含文件的文件名,以及该文件名对应的inode号码。
ls命令只列出目录文件中的所有文件名:
ls-i命令列出整个目录文件,即文件名和inode号码:
如果要查看文件的详细信息,就必须根据inode号码,访问inode节点,读取信息。ls-l命令列出文件的详细信息。
一般情况下,文件名和inode号码是"一一对应"关系,每个inode号码对应一个文件名。但是,Unix/Linux系统允许,多个文件名指向同一个inode号码。这意味着,可以用不同的文件名访问同样的内容;对文件内容进行修改,会影响到所有文件名;但是,删除一个文件名,不影响另一个文件名的访问。这种情况就被称为"硬链接"(hard link)。
运行上面这条命令以后,源文件与目标文件的inode号码相同,都指向同一个inode。inode信息中有一项叫做"链接数",记录指向该inode的文件名总数,这时就会增加1。反过来,删除一个文件名,就会使得inode节点中的"链接数"减1。当这个值减到0,表明没有文件名指向这个inode,系统就会回收这个inode号码,以及其所对应block区域。
这里顺便说一下目录文件的"链接数"。创建目录时,默认会生成两个目录项:"."和".."。前者的inode号码就是当前目录的inode号码,等同于当前目录的"硬链接";后者的inode号码就是当前目录的父目录的inode号码,等同于父目录的"硬链接"。所以,任何一个目录的"硬链接"总数,总是等于2加上它的子目录总数(含隐藏目录),这里的2是父目录对其的“硬链接”和当前目录下的".硬链接“。
除了硬链接以外,还有一种特殊情况。文件A和文件B的inode号码虽然不一样,但是文件A的内容是文件B的路径。读取文件A时,系统会自动将访问者导向文件B。因此,无论打开哪一个文件,最终读取的都是文件B。这时,文件A就称为文件B的"软链接"(soft link)或者"符号链接(symbolic link)。
这意味着,文件A依赖于文件B而存在,如果删除了文件B,打开文件A就会报错:"No such file or directory"。这是软链接与硬链接最大的不同:文件A指向文件B的文件名,而不是文件B的inode号码,文件B的inode"链接数"不会因此发生变化。
ln-s源文文件或目录目标文件或目录
由于inode号码与文件名分离,这种机制导致了一些Unix/Linux系统特有的现象。
1.有时,文件名包含特殊字符,无法正常删除。这时,直接删除inode节点,就能起到删除文件的作用。
2.移动文件或重命名文件,只是改变文件名,不影响inode号码。
3.打开一个文件以后,系统就以inode号码来识别这个文件,不再考虑文件名。因此,通常来说,系统无法从inode号码得知文件名。
第3点使得软件更新变得简单,可以在不关闭软件的情况下进行更新,不需要重启。因为系统通过inode号码,识别运行中的文件,不通过文件名。更新的时候,新版文件以同样的文件名,生成一个新的inode,不会影响到运行中的文件。等到下一次运行这个软件的时候,文件名就自动指向新版文件,旧版文件的inode则被回收。
在一台配置较低的Linux服务器(内存、硬盘比较小)的/data分区内创建文件时,系统提示磁盘空间不足,用df-h命令查看了一下磁盘使用情况,发现/data分区只使用了66%,还有12G的剩余空间,按理说不会出现这种问题。后来用df-i查看了一下/data分区的索引节点(inode),发现已经用满(IUsed=100%),导致系统无法创建新目录和文件。
/data/cache目录中存在数量非常多的小字节缓存文件,占用的Block不多,但是占用了大量的inode。
1、删除/data/cache目录中的部分文件,释放出/data分区的一部分inode。
2、用软连接将空闲分区/opt中的newcache目录连接到/data/cache,使用/opt分区的inode来缓解/data分区inode不足的问题:
三、linux 删除0字节和替换0字节文件的脚本怎么写
Linux系统信息存放在文件里,文件与普通的公务文件类似。每个文件都有自己的名字、内容、存放地址及其它一些管理信息,如文件的用户、文件的大小等。文件可以是一封信、一个通讯录,或者是程序的源语句、程序的数据,甚至可以包括可执行的程序和其它非正文内容。 Linux文件系统具有良好的结构,系统提供了很多文件处理程序。这里主要介绍常用的文件处理命令。
file通过探测文件内容判断文件类型,使用权限是所有用户。
-v:在标准输出后显示版本信息,并且退出。
-f name:从文件namefile中读取要分析的文件名列表。
使用file命令可以知道某个文件究竟是二进制(ELF格式)的可执行文件,还是Shell Script文件,或者是其它的什么格式。file能识别的文件类型有目录、Shell脚本、英文文本、二进制可执行文件、C语言源文件、文本文件、DOS的可执行文件。
如果我们看到一个没有后缀的文件grap,可以使用下面命令:
此时系统显示这是一个英文文本文件。需要说明的是,file命令不能探测包括图形、音频、视频等多媒体文件类型。
mkdir命令的作用是建立名称为dirname的子目录,与MS DOS下的md命令类似,它的使用权限是所有用户。
-m,--mode=模式:设定权限<模式>,与chmod类似。
-p,--parents:需要时创建上层目录;如果目录早已存在,则不当作错误。
-v,--verbose:每次创建新目录都显示信息。
--version:显示版本信息后离开。
在进行目录创建时可以设置目录的权限,此时使用的参数是“-m”。假设要创建的目录名是“tsk”,让所有用户都有rwx(即读、写、执行的权限),那么可以使用以下命令:
grep命令可以指定文件中搜索特定的内容,并将含有这些内容的行标准输出。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
-I:不区分大小写(只适用于单字符)。
-h:查询多文件时不显示文件名。
-l:查询多文件时只输出包含匹配字符的文件名。
-s:不显示不存在或无匹配文本的错误信息。
-v:显示不包含匹配文本的所有行。
\\:忽略正则表达式中特殊字符的原有含义。
\\<:从匹配正则表达式的行开始。
\\>:到匹配正则表达式的行结束。
[ ]:单个字符,如[A]即A符合要求。
[- ]:范围,如[A-Z],即A、B、C一直到Z都符合要求。
正则表达式是Linux/Unix系统中非常重要的概念。正则表达式(也称为“regex”或“regexp”)是一个可以描述一类字符串的模式(Pattern)。如果一个字符串可以用某个正则表达式来描述,我们就说这个字符和该正则表达式匹配(Match)。这和DOS中用户可以使用通配符“*”代表任意字符类似。在Linux系统上,正则表达式通常被用来查找文本的模式,以及对文本执行“搜索-替换”操作和其它功能。
查询DNS服务是日常工作之一,这意味着要维护覆盖不同网络的大量IP地址。有时IP地址会超过2000个。如果要查看nnn.nnn网络地址,但是却忘了第二部分中的其余部分,只知到有两个句点,例如nnn nn..。要抽取其中所有nnn.nnn IP地址,使用[0-9 ]\\\\.[0-0\\\\。含义是任意数字出现3次,后跟句点,接着是任意数字出现3次,后跟句点。
$grep'[0-9 ]\\\\.[0-0\\\\' ipfile
补充说明,grep家族还包括fgrep和egrep。fgrep是fix grep,允许查找字符串而不是一个模式;egrep是扩展grep,支持基本及扩展的正则表达式,但不支持\\q模式范围的应用及与之相对应的一些更加规范的模式。
dd命令用来复制文件,并根据参数将数据转换和格式化。
bs=字节:强迫 ibs=<字节>及obs=<字节>。
cbs=字节:每次转换指定的<字节>。
conv=关键字:根据以逗号分隔的关键字表示的方式来转换文件。
count=块数目:只复制指定<块数目>的输入数据。
ibs=字节:每次读取指定的<字节>。
if=文件:读取<文件>内容,而非标准输入的数据。
obs=字节:每次写入指定的<字节>。
of=文件:将数据写入<文件>,而不在标准输出显示。
seek=块数目:先略过以obs为单位的指定<块数目>的输出数据。
skip=块数目:先略过以ibs为单位的指定<块数目>的输入数据。
dd命令常常用来制作Linux启动盘。先找一个可引导内核,令它的根设备指向正确的根分区,然后使用dd命令将其写入软盘:
上面代码说明,使用rdev命令将可引导内核vmlinuz中的根设备指向/dev/hda,请把“hda”换成自己的根分区,接下来用dd命令将该内核写入软盘。
find命令的作用是在目录中搜索文件,它的使用权限是所有用户。
find [path][option*][**pression]
path指定目录路径,系统从这里开始沿着目录树向下查找文件。它是一个路径列表,相互用空格分离,如果不写path,那么默认为当前目录。
-depth:使用深度级别的查找过程方式,在某层指定目录中优先查找文件内容。
-maxdepth levels:表示至多查找到开始目录的第level层子目录。level是一个非负数,如果level是0的话表示仅在当前目录中查找。
-mindepth levels:表示至少查找到开始目录的第level层子目录。
-mount:不在其它文件系统(如Msdos、Vfat等)的目录和文件中查找。
[expression]是匹配表达式,是find命令接受的表达式,find命令的所有操作都是针对表达式的。它的参数非常多,这里只介绍一些常用的参数。
-atime n:搜索在过去n天读取过的文件。
-ctime n:搜索在过去n天修改过的文件。
-group grpoupname:搜索所有组为grpoupname的文件。
-user用户名:搜索所有文件属主为用户名(ID或名称)的文件。
-size n:搜索文件大小是n个block的文件。
-print:输出搜索结果,并且打印。
例如,我们想要查找一个文件名是lilo.conf的文件,可以使用如下命令:
find命令后的“/”表示搜索整个硬盘。
根据文件名查找文件会遇到一个实际问题,就是要花费相当长的一段时间,特别是大型Linux文件系统和大容量硬盘文件放在很深的子目录中时。如果我们知道了这个文件存放在某个目录中,那么只要在这个目录中往下寻找就能节省很多时间。比如smb.conf文件,从它的文件后缀“.conf”可以判断这是一个配置文件,那么它应该在/etc目录内,此时可以使用下面命令:
这样,使用“快速查找文件”方式可以缩短时间。
有时我们知道只某个文件包含有abvd这4个字,那么要查找系统中所有包含有这4个字符的文件可以输入下面命令:
输入这个命令以后,Linux系统会将在/目录中查找所有的包含有abvd这4个字符的文件(其中*是通配符),比如abvdrmyz等符合条件的文件都能显示出来。
find命令可以使用混合查找的方法,例如,我们想在/etc目录中查找大于500000字节,并且在24小时内修改的某个文件,则可以使用-and(与)把两个查找参数链接起来组合成一个混合的查找方式。
find/etc-size+500000c-and-mtime+1
mv命令用来为文件或目录改名,或者将文件由一个目录移入另一个目录中,它的使用权限是所有用户。该命令如同DOS命令中的ren和move的组合。
mv[options]源文件或目录目标文件或目录
-i:交互方式操作。如果mv操作将导致对已存在的目标文件的覆盖,此时系统询问是否重写,要求用户回答“y”或“n”,这样可以避免误覆盖文件。
-f:禁止交互操作。mv操作要覆盖某个已有的目标文件时不给任何指示,指定此参数后i参数将不再起作用。
(1)将/usr/cbu中的所有文件移到当前目录(用“.”表示)中:
(2)将文件cjh.txt重命名为wjz.txt:
ls命令用于显示目录内容,类似DOS下的dir命令,它的使用权限是所有用户。
-a,--all:不隐藏任何以“.”字符开始的项目。
-A,--almost-all:列出除了“.”及“..”以外的任何项目。
--author:印出每个文件著作者。
-b,--escape:以八进制溢出序列表示不可打印的字符。
--block-size=大小:块以指定<大小>的字节为单位。
-B,--ignore-backups:不列出任何以~字符结束的项目。
-f:不进行排序,-aU参数生效,-lst参数失效。
-F,--classify:加上文件类型的指示符号(*/=@|其中一个)。
-g:like-l, but do not list owner。
-G,--no-group:inhibit display of group information。
-i,--inode:列出每个文件的inode号。
-I,--ignore=样式:不印出任何符合Shell万用字符<样式>的项目。
-L,--dereference:当显示符号链接的文件信息时,显示符号链接所指示的对象,而并非符号链接本身的信息。
-m:所有项目以逗号分隔,并填满整行行宽。
-n,--numeric-uid-gid:类似-l,但列出UID及GID号。
-N,--literal:列出未经处理的项目名称,例如不特别处理控制字符。
-p,--file-type:加上文件类型的指示符号(/=@|其中一个)。
-Q,--quote-name:将项目名称括上双引号。
-r,--reverse:依相反次序排列。
-R,--recursive:同时列出所有子目录层。
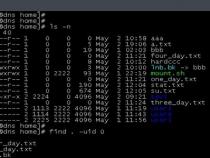
ls命令是Linux系统使用频率最多的命令,它的参数也是Linux命令中最多的。使用ls命令时会有几种不同的颜色,其中蓝色表示是目录,绿色表示是可执行文件,红色表示是压缩文件,浅蓝色表示是链接文件,加粗的黑色表示符号链接,灰色表示是其它格式文件。ls最常使用的是ls- l,见图1所示。
文件类型开头是由10个字符构成的字符串。其中第一个字符表示文件类型,它可以是下述类型之一:-(普通文件)、d(目录)、l(符号链接)、b(块设备文件)、c(字符设备文件)。后面的9个字符表示文件的访问权限,分为3组,每组3位。第一组表示文件属主的权限,第二组表示同组用户的权限,第三组表示其他用户的权限。每一组的三个字符分别表示对文件的读(r)、写(w)和执行权限(x)。对于目录,表示进入权限。s表示当文件被执行时,把该文件的 UID或GID赋予执行进程的UID(用户ID)或GID(组 ID)。t表示设置标志位(留在内存,不被换出)。如果该文件是目录,那么在该目录中的文件只能被超级用户、目录拥有者或文件属主删除。如果它是可执行文件,那么在该文件执行后,指向其正文段的指针仍留在内存。这样再次执行它时,系统就能更快地装入该文件。接着显示的是文件大小、生成时间、文件或命令名称。
diff命令用于两个文件之间的比较,并指出两者的不同,它的使用权限是所有用户。
-a:将所有文件当作文本文件来处理。
-H:利用试探法加速对大文件的搜索。
cmp(“compare”的缩写)命令用来简要指出两个文件是否存在差异,它的使用权限是所有用户。
-l:将字节以十进制的方式输出,并方便将两个文件中不同的以八进制的方式输出。
cat(“concatenate”的缩写)命令用于连接并显示指定的一个和多个文件的有关信息,它的使用权限是所有用户。
-n:由第一行开始对所有输出的行数编号。
-b:和-n相似,只不过对于空白行不编号。
-s:当遇到有连续两行以上的空白行时,就代换为一行的空白行。
(1)cat命令一个最简单的用处是显示文本文件的内容。例如,我们想在命令行看一下README文件的内容,可以使用命令:
(2)有时需要将几个文件处理成一个文件,并将这种处理的结果保存到一个单独的输出文件。cat命令在其输入上接受一个或多个文件,并将它们作为一个单独的文件打印到它的输出。例如,把README和INSTALL的文件内容加上行号(空白行不加)之后,将内容附加到一个新文本文件File1中:
(3)cat还有一个重要的功能就是可以对行进行编号,见图2所示。这种功能对于程序文档的编制,以及法律和科学文档的编制很方便,打印在左边的行号使得参考文档的某一部分变得容易,这些在编程、科学研究、业务报告甚至是立法工作中都是非常重要的。
图2使用cat命令/etc/named.conf文件进行编号
对行进行编号功能有-b(只能对非空白行进行编号)和-n(可以对所有行进行编号)两个参数:
ln命令用来在文件之间创建链接,它的使用权限是所有用户。
-d:允许系统管理者硬链结自己的目录。
-s:进行软链结(Symbolic Link)。
-b:将在链结时会被覆盖或删除的文件进行备份。
链接有两种,一种被称为硬链接(Hard Link),另一种被称为符号链接(Symbolic Link)。默认情况下,ln命令产生硬链接。
硬连接指通过索引节点来进行的连接。在Linux的文件系统中,保存在磁盘分区中的文件不管是什么类型都给它分配一个编号,称为索引节点号(Inode Index)。在Linux中,多个文件名指向同一索引节点是存在的。一般这种连接就是硬连接。硬连接的作用是允许一个文件拥有多个有效路径名,这样用户就可以建立硬连接到重要文件,以防止“误删”的功能。其原因如上所述,因为对应该目录的索引节点有一个以上的连接。只删除一个连接并不影响索引节点本身和其它的连接,只有当最后一个连接被删除后,文件的数据块及目录的连接才会被释放。也就是说,文件才会被真正删除。
与硬连接相对应,Lnux系统中还存在另一种连接,称为符号连接(Symbilc Link),也叫软连接。软链接文件有点类似于Windows的快捷方式。它实际上是特殊文件的一种。在符号连接中,文件实际上是一个文本文件,其中包含的有另一文件的位置信息。
上面我们介绍了Linux文件处理命令,下面介绍几个实例,大家可以动手练习一下刚才讲过的命令。
1.利用符号链接快速访问关键目录
符号链接是一个非常实用的功能。假设有一些目录或文件需要频繁使用,但由于Linux的文件和目录结构等原因,这个文件或目录在很深的子目录中。比如, Apache Web服务器文档位于系统的/usr/local/httpd/htdocs中,并且不想每次都要从主目录进入这样一个长的路径之中(实际上,这个路径也非常不容易记忆)。
为了解决这个问题,可以在主目录中创建一个符号链接,这样在需要进入该目录时,只需进入这个链接即可。
为了能方便地进入Web服务器(/usr/local/httpd/htdocs)文档所在的目录,在主目录下可以使用以下命令:
$ ln-s/usr/local/httpd/htdocs gg
这样每次进入gg目录就可访问Web服务器的文档,以后如果不再访问Web服务器的文档时,删除gg即可,而真正的Web服务器的文档并没有删除。
2.使用dd命令将init.rd格式的root.ram内容导入内存
grep是Linux/Unix中使用最广泛的命令之一,许多Linux系统内部都可以调用它。
(1)如果要查询目录列表中的目录,方法如下:
(2)如果在一个目录中查询不包含目录的所有文件,方法如下:
(3)用find命令调用grep,如所有C源代码中的“Chinput”,方法如下:
$find/ZhXwin-name*.c-exec grep-q-s Chinput{}\\;-print