python如何提取或抓取一张图片里的文字,有哪位大神指导方
发布时间:2025-05-11 22:14:52 发布人:远客网络
一、python如何提取或抓取一张图片里的文字,有哪位大神指导方
1、我面临一个需求,即从多张图片中识别出文字内容,但发现市面上的工具多只能逐张处理,且准确率不高。
2、为解决此问题,我利用Python编写了一段脚本,实现批量处理功能。首先,确保图片文件位于同一文件夹内,使用os模块的listdir方法获取所有文件路径,再通过for循环结合with open方法逐个读取。
3、这里使用百度API进行文字识别。您需要一个百度账号,登录后访问通用文字识别的网页,创建应用并获取AppID、API Key、Secret Key。请确保申请了资源,否则应用无法使用。获取这些信息后,即可编写代码。
4、使用百度API的Python SDK,创建AipOcr客户端。
5、在代码中,需将APP_ID、API_KEY与SECRET_KEY替换为从百度智能云获取的实际值。这些值在应用创建后由系统分配,用于验证身份并进行请求签名。
6、完成客户端创建后,即可调用API对图片进行文字识别。识别结果将以JSON格式返回,需从中解析出文字内容。
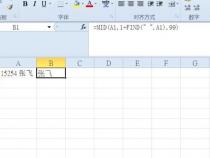
7、解析JSON结果,提取文字列表。遍历列表,获取所有文字信息。
8、最后,将识别出的文字内容保存到Word文档中。
二、python怎么抓取网页中DIV的文字
确定下载目标,找到网页,找到网页中需要的内容。对数据进行处理。保存数据。
1)确定网络中需要的信息,打开网页后使用F12打开开发者模式。
在Network中可以看到很多信息,我们在页面上看到的文字信息都保存在一个html文件中。点击文件后可以看到response,文字信息都包含在response中。
对于需要输入的信息,可以使用ctrl+f,进行搜索。查看信息前后包含哪些特定字段。
对于超链接的提取,可以使用最左边的箭头点击超链接,这时Elements会打开有该条超链接的信息,从中判断需要提取的信息。从下载小说来看,在目录页提取出小说的链接和章节名。
输入字符集一定要设置成utf-8。页面大多为GBK字符集。不设置会乱码。
三、Python 自动识别图片或视频里的文字
Python自动识别图片和视频中的文字是一项实用技术,尽管市面上有许多库,但识别效果可能不尽如人意。经过实践验证,阿里ModelScope社区的"OCR-多场景文字识别"大模型在图片文字识别上表现出色,能够准确捕捉图片中的各种文字信息。
调用此大模型的Python代码示例适用于单张图片识别,对于批量图片,可以进行扩展。该模型基于TensorFlow 1.15.x运行,需要确保Python版本在3.5-3.8之间。在测试过程中,可能会遇到版本兼容性问题,通过安装必要的依赖包,如指定的版本,一般可以解决。
程序运行后,输出的格式可以根据实际需求调整。对于视频识别,由于模型本身不直接处理视频,我们可以借助FFMPEG将视频拆分为帧,逐帧进行文字识别。这需要处理好帧率和完整性问题,如避免丢帧或漏处理。如需进一步讨论,可通过私信交流。
以下命令示例展示了如何使用FFMPEG从视频中提取每秒一帧的图片,以指定格式保存。这样,无论是图片还是视频,Python都能辅助我们实现文字的高效识别。